
From Chaos to Clarity: How I built a RAG-powered Multi-Agent System That Plans Like a Pro
1. Introduction to Travel AI system
Travelers face challenges in identifying optimal destinations aligned with their personal preferences, constructing efficient itineraries, and obtaining authentic pre-trip insights due to information overload, fragmented travel information, uncertainty regarding on-site conditions (including climate, atmosphere, and footfall / crowd volume), and unclear cost burden.
1.1 Key pain points
a. Lack of unbiased, genuine source of information: For digital-savvy, upwardly mobile but budget-conscious traveler segment, planning a trip can be frustrating and time-consuming. While there are popular online itinerary planners from industry leaders such as Expedia, these tools primarily serve as vendor-driven marketplaces rather than objective travel advisory. The search results and recommendations are often skewed by sponsored listings, pushing specific hotels, flights, and experiences that may or may not optimize for travelers’ interests. Thus, users are left with the option of browsing through an overwhelming volume of content themselves.
b. Decision fatigue and suboptimal travel experience: Travelers, despite hyper connectivity, face FOMO (fear of missing out) due to the sheer influx of content across social media and travel websites, making it difficult to determine what is truly worth experiencing. Existing tools provide generic information but fail to give real-time, contextual insights into destinations—such as actual crowd levels, local weather conditions, or a location’s current vibe. Thus, there is a lot of uncertainty about whether their chosen spots will match their expectations. Price sensitive groups also find it hard to get a realistic estimate of their total trip costs.
1.2 Proposed solution
The solution is a next-generation AI travel assistant powered by a RAG (Retrieval-Augmented Generation) and multi-agent system architecture that aggregates, analyzes, and personalizes travel information from diverse sources.
- Unlike traditional itinerary planners that primarily serve vendor interests, this AI assistant will act as an unbiased, intelligent advisor, helping users discover destinations, build optimized itineraries, and make data-driven travel decisions based on their unique preferences, constraints, and real-time conditions.
- The system will leverage multi-agent coordination to collect and process data from multiple sources, including real-time weather reports, footfall density analysis, cost estimations, and user-generated reviews.
- Using vector embeddings and a scalable knowledge base, the assistant will provide hyper-personalized recommendations, avoiding the noise of paid promotions and instead focusing on authentic, data-backed insights.
- It will predict potential trip expenses based on dynamic pricing trends and offer realistic previews of destinations—including expected crowd levels, atmosphere, and local conditions—ensuring users make informed choices. By eliminating information overload and uncertainty, this AI assistant will help budget-conscious travelers maximize their experience while staying within their financial limits.
- The look and feel of the final product for the user will be of a state-of-art digital tool that provides dynamic and interactive visualization of the tool’s outputs optimized for the users’ preferences such as timing, budget, group travelling, and fun preferences.
1.3 Tooling Used
Following is the tooling used for buidling the current MVP of this system.
| Process | Tool used | Tool functionality |
|---|---|---|
| Vector database | FAISS | Chosen for its high-speed and scalable similarity search capabilities, enabling quick retrieval of relevant travel data from large-scale embeddings. |
| Embedding model | OpenAIEmbeddings | Selected for its optimized balance of performance and speed in generating vector embeddings, ensuring efficient retrieval of relevant travel information. |
| Orchestration | LangGraph | Used for managing multi-agent workflows, allowing structured interactions between different agents in a RAG-based system to enhance contextual understanding and response generation. |
| LLM | OpenAI GPT 3.5 | Chosen for its cost-effective yet powerful natural language understanding and generation capabilities, balancing efficiency and affordability for handling user queries. |
| Evaluation | RAGAS | Used for assessing the quality of retrieval-augmented generation outputs, helping to fine-tune responses by measuring factual accuracy, relevance, and coherence. |
| User interface | Streamlit and Hugging Face | Hugging Face is chosen for hosting and deploying AI models, while Streamlit provides an interactive and conversational UI for seamless user experience in itinerary planning. |
2. Data sourcing system
The data preparation module of the Travel AI system is responsible for sourcing data from the preliminary data sources chosen for the MVP build, and creating a rich, travel-context knowledge base that is ready for downstream consumption by the RAG system.
| Module summary: |
|---|
| Description: Module leveraging multiple data sources, combining structured travel API data with unstructured encyclopaedic content to build a comprehensive vector database, to create a rich, contextual knowledge base |
| Input: Raw data from two prioritized data sources – Amadeus API and WikiVoyager |
| Output: Vector database object of ~5k documents |
| Upcoming improvisations: Expanding data sources in scope by including more external APIs such as Skyscanner API, TripAdvisor API, and additional travel web sources such as Culture Trip, and Travel Stack Exchange |
Data sources in scope of current MVP build:
The system employs a modular approach to data collection, enrichment, and storage. I have integrated data from the following two sources:
1. Amadeus Travel API: Provides structured travel information including flight offers, hotel listings, and popular destinations.
2. WikiVoyage: Offers rich, human-curated travel content including cultural context, local transportation, attractions, and dining options
I combine these sources using LangChain’s document-based architecture and store them in a FAISS vector store using OpenAI’s embedding model.
2.1 Data Acquisition and Enrichment / Content Extraction and Enrichment from WikiVoyage
This section focused on acquiring data from WikiVoyage and preparing it for ingestion into RAG pipelines. For this, I have written the following wrapper functions:
• fetch_enriched_destination_info(): creates enriched, comprehensive destination guides for 5 major cities (which is easily extensible to many more cities) as a LangChain Document with content and metadata (allowing for better searchability) and structured for addition to a vector store object (for storage)
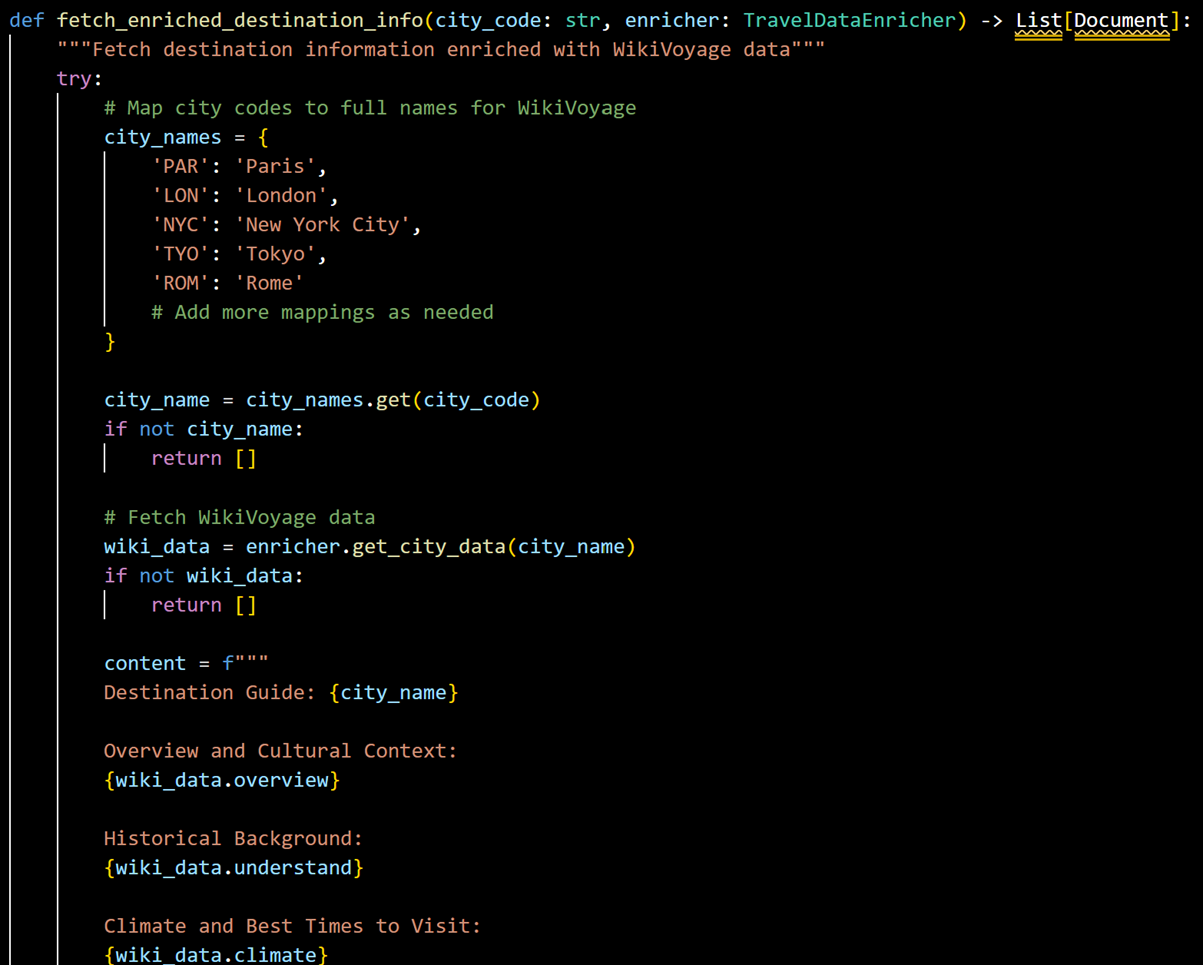 Example of fetch_enriched_destination_info()
Example of fetch_enriched_destination_info()
• fetch_enriched_hotel_information(): creates enriched hotel documents by adding additional context from WikiVoyage including city overview, local transport info, attractions, and dining scene, for each hotel for the mentioned cities, returning a list of enriched Document objects. The functions use the following custom classes:
• TravelDataEnricher: handles fetching and processing travel-related data from WikiVoyage via core methods for
- data cleaning: clean text by removing markup, HTML tags, and formatting,
- section extraction: extract specific sections, and
- city data retrieval: structure city data
• WikiVoyageData: extracts content from WikiVoyage into 7 key fields (destination overview, historical background, and info about climate info, transport info, attractions, food, and events) structuring it in a standardized format making it easier to consistently process and present information about different destinations in a uniform way throughout the app. This content extraction and standardization of data structure allows for:
- consistent data extraction from WikiVoyage,
- standardized processing of travel information,
- efficient storage and retrieval of travel data, and
- scalable expansion of input data for the app (to include more locations and information)
2.2 Structured Travel Data Collection from Amadeus API
This sub-module interfaces with the Amadeus API to collect structured travel data. For this, I have written the following wrapper functions:
• fetch_flight_offers(): Retrieves flight information between origin-destination pairs and for each flight found, it fetches information such as itinerary details, pricing information, flight segment analysis, arrival and departure details, and more. It returns a Document object with all these details. • fetch_popular_destinations(): Identifies trending destinations from a given origin by making an API call to Amadeus to get popular flight destinations from a particular city. For now, this is used only for NYC as an example but can be easily invoked for any city by expanding the list and thus, broadening the data extracted. • fetch_hotel_information(): Gets hotel listings for specific cities, and for each hotel extracted, collates hotel details (name, chain info, guest services, neighborhood and location context based on coordinates, transportation access information, etc) and further calls functions such as generate_detailed_amenities, generate_neighborhood_context, and determine_hotel_category to generate these field-specific content, returning Document objects on hotels.
Each function is basically enriching the raw API data with additional context.
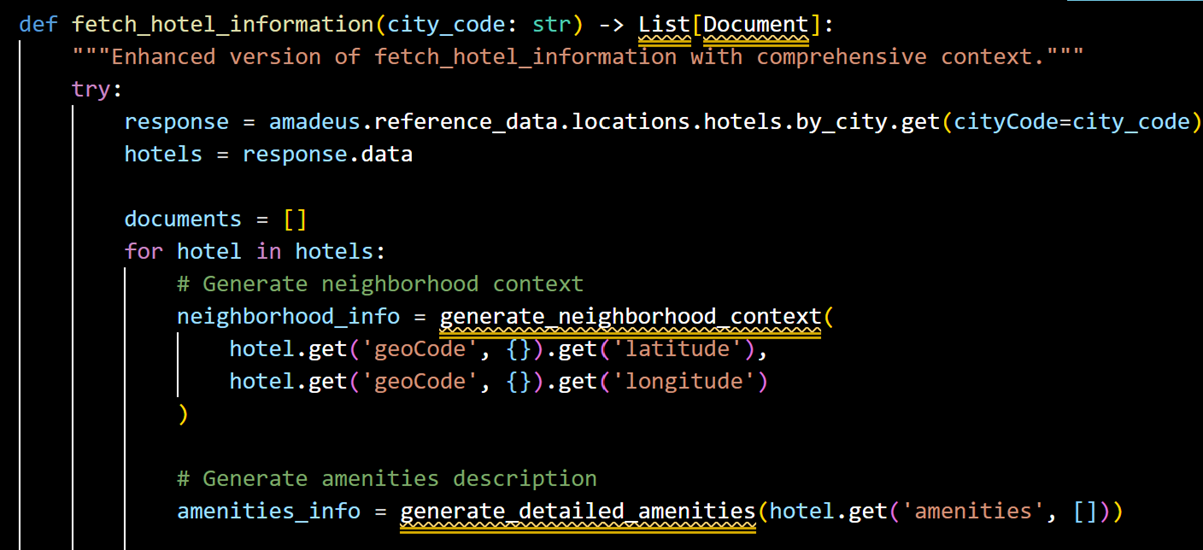 Example of fetch_hotel_information() returning list of enriched hotel information documents
Example of fetch_hotel_information() returning list of enriched hotel information documents
2.3 Content Generation Strategies
The system employs template-based content generation to create rich, structured documents. generate_airport_information, generate_nearby_attractions, generate_neighborhood_context, and generate_detailed_amenities are currently template generators. This means they return the same template text regardless of the input parameters, serving as a placeholder structure for route analysis rather than providing actual dynamic analysis.
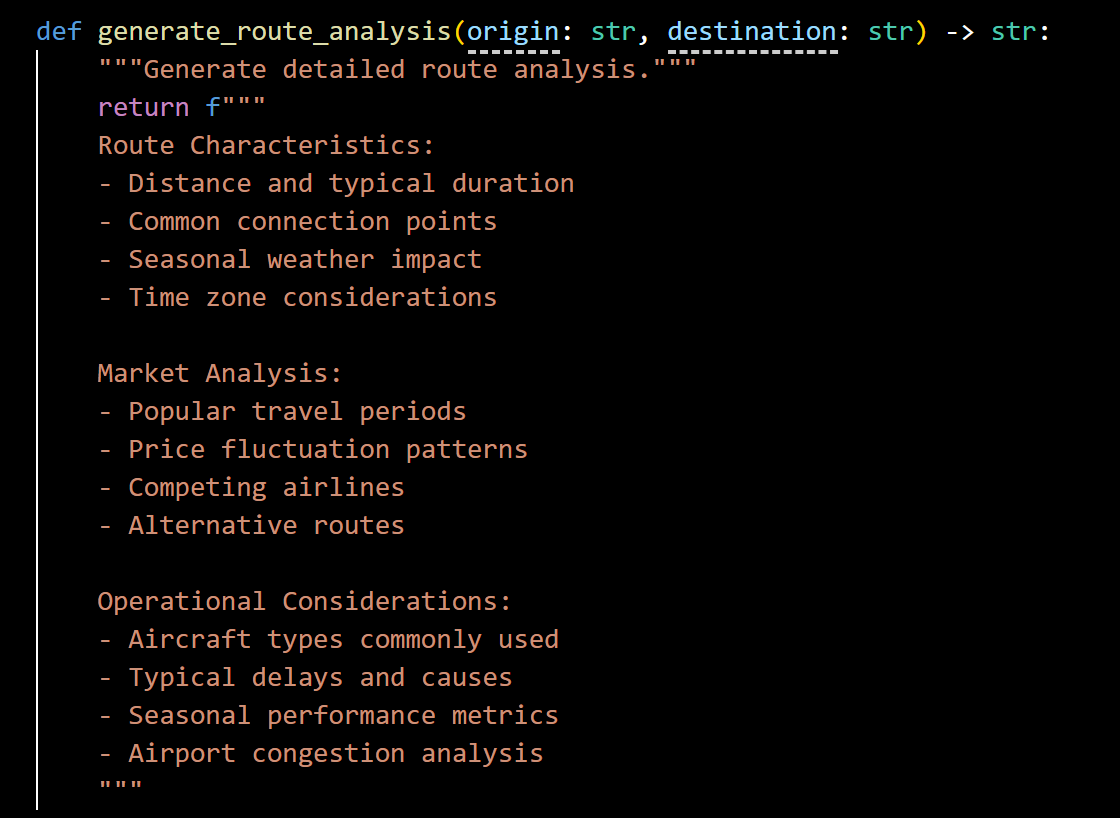 Example of generate_route_analysis() providing template of standardized route information
Example of generate_route_analysis() providing template of standardized route information
This approach ensures consistent document structure, provides placeholders for information that might not be available via API, and creates a rich context that LLMs can leverage for generating responses.
2.4 Consolidated Knowledge Base Construction
build_enriched_travel_knowledge_base(): combines the different data sources, collects destination information from WikiVoyage, retrieves popular destinations from Amadeus, fetches hotel information and enriches it with location context, collects flight offers between popular city pairs, processes and splits all documents, and embeds the content into a FAISS vector store.
For document processing, I use LangChain’s RecursiveCharacterTextSplitter to create:
• 4000-character chunks balancing context preservation with retrieval granularity,
• 400-character overlap to prevent loss of important context at chunk boundaries, and
• a separator hierarchy occurring in natural documents.
The documents created are embedded using OpenAI’s embedding model, creating a searchable semantic index, in a FAISS vector store.
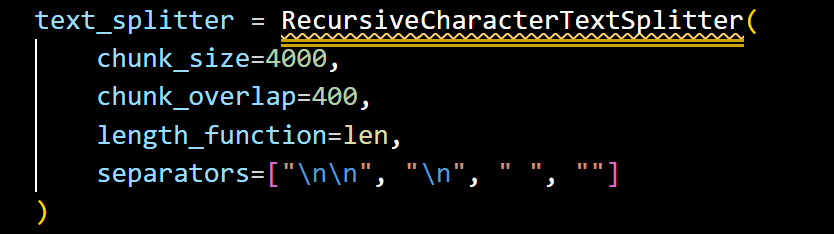 Document chunking strategy
Document chunking strategy
As shown in the final document summary statistics, this pipeline has successfully:
• created a substantial knowledge base (5031 documents),
• maintained consistent document length (most documents are ~4k characters long), and
• achieved decent content density (averaging ~3k characters per doc)
Final output: The resulting knowledge base provides a rich foundation for building intelligent travel applications, with documents that combine factual travel information with cultural context and local insights. This shows how we can combine traditional structured data APIs with rich unstructured content to create contextual, semantically searchable knowledge databases.
Steps for enhancement of Travel AI wrt Data Sourcing:
- Addition of data sources:
- External Travel APIs providing structured data that can be easily integrated into Python-based data pipelines using libraries like requests, and pandas for efficient retrieval and processing such as structured data that can be easily integrated into Python-based data pipelines using libraries like requests, pandas, and asyncio for efficient retrieval and processing such as TripAdvisor API and Skyscanner API.
- Unstructured online sources providing structured and semi-structured text data that can be scraped or accessed using Python libraries like BeautifulSoup, Scrapy, or newspaper3k such as Lonely Planet, and Travel Stack Exchange.
- Alternate chunking strategies: Few alternative approaches here could be using hierarchical chunking strategies, implementing domain-specific document splitting based on travel content structure, or experimenting with other embedding models like BERT or sentence-transformers. Experimenting with these alternate options and analysing their impact on RAG performance can be a valuable lever to work on.
- Alternate content extraction strategies: Testing alternatives for content extraction from WikiVoyage could include using a full-text extraction library like Beautiful Soup, implementing a more sophisticated entity resolution system for city name matching, or using the WikiMedia API directly instead of the mwclient wrapper currently used to define TravelDataEnricher class.
- Expansion of list of cities: and more attributes like flight routes in the data sourcing functions.
3. Agent Architecture and Orchestration
The Agent Architecture module constitues the cognitive backbone of the Travel AI system, transforming the raw knowledge base into an intelligent, interactive assistant capable of understanding and responding to complex travel queries. This module implements a sophisticated multi-agent system orchestrated with LangGraph to provide specialized travel planning capabilities. The integration of RAG technology ensures that responses are grounded in factual information, while still leveraging the language capabilities of modern LLMs.
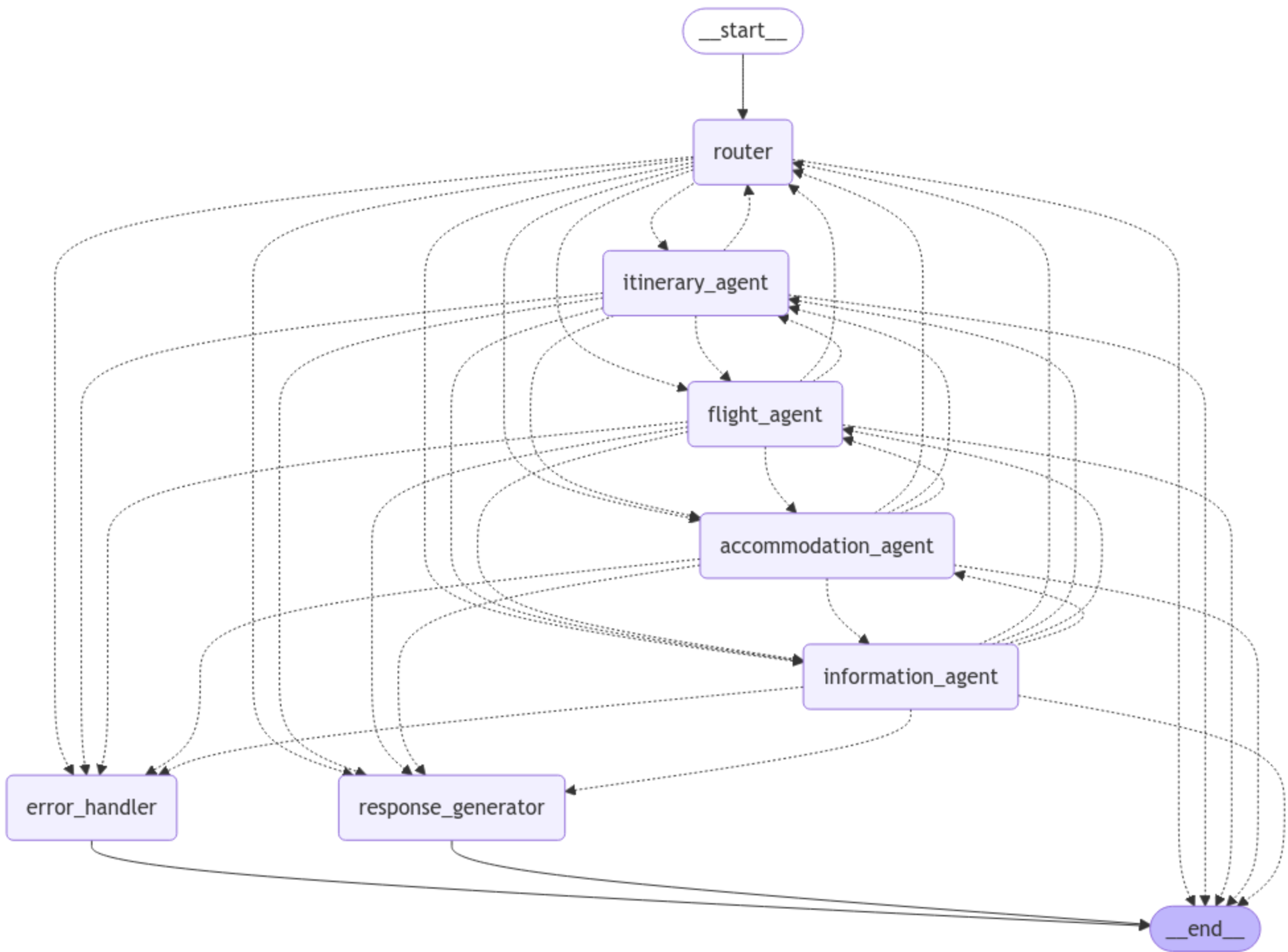 Multi-agent architecture of Travel AI System
Multi-agent architecture of Travel AI System
| Description: An orchestrated multi-agent system that routes user queries to specialized agents, processes them using RAG (Retrieval-Augmented Generation), and delivers polished, contextual responses tailored to specific travel planning needs. |
|---|
| Input: User travel queries and the vector knowledge base created in the Data Preparation module |
| Output: Comprehensive, context-rich responses for itinerary planning, flight information, accommodation recommendations, and general travel information |
| Upcoming improvisations: Experimentation and testing of other options for every design choice such as LLMs, embedding model, components of multi-agent system, and more |
3.1 Core Architecture Components
The agent system is built on a state-based architecture using LangGraph, which provides a flexible framework for creating complex agent workflows.
3.1.1 State Management System
The AgentState class acts as a central repository for tracking conversation context, agent decisions, and response generation.
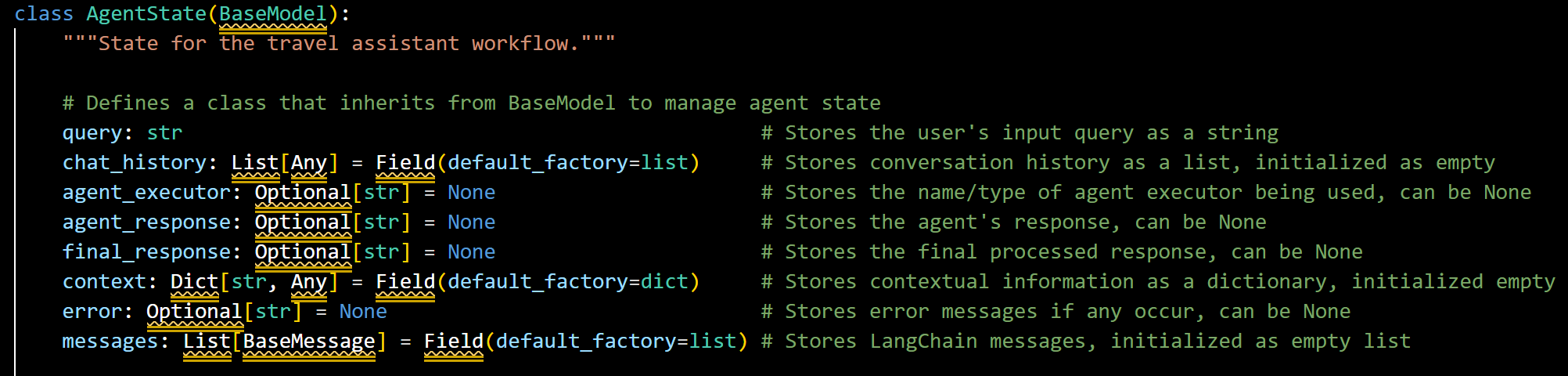 Snapshot of Agent State
Snapshot of Agent State
- This state object serves several critical functions such as conversation persistence (maintaining history across turns), context accumulation and knowledge building about user preferences, agent coordination (for communication between specialized agents), and error handling.
- State management is needed to enable complex, multi-turn interactions where context is preserved and enhanced with each exchange. This is particularly essential for travel planning, which involves iterative refinement of preferences and constraints.
3.1.2 Router Agent: Intelligent Query Classification
The router agent serves as the entry point to the system, analysing user queries and determining which specialized agent should handle them:
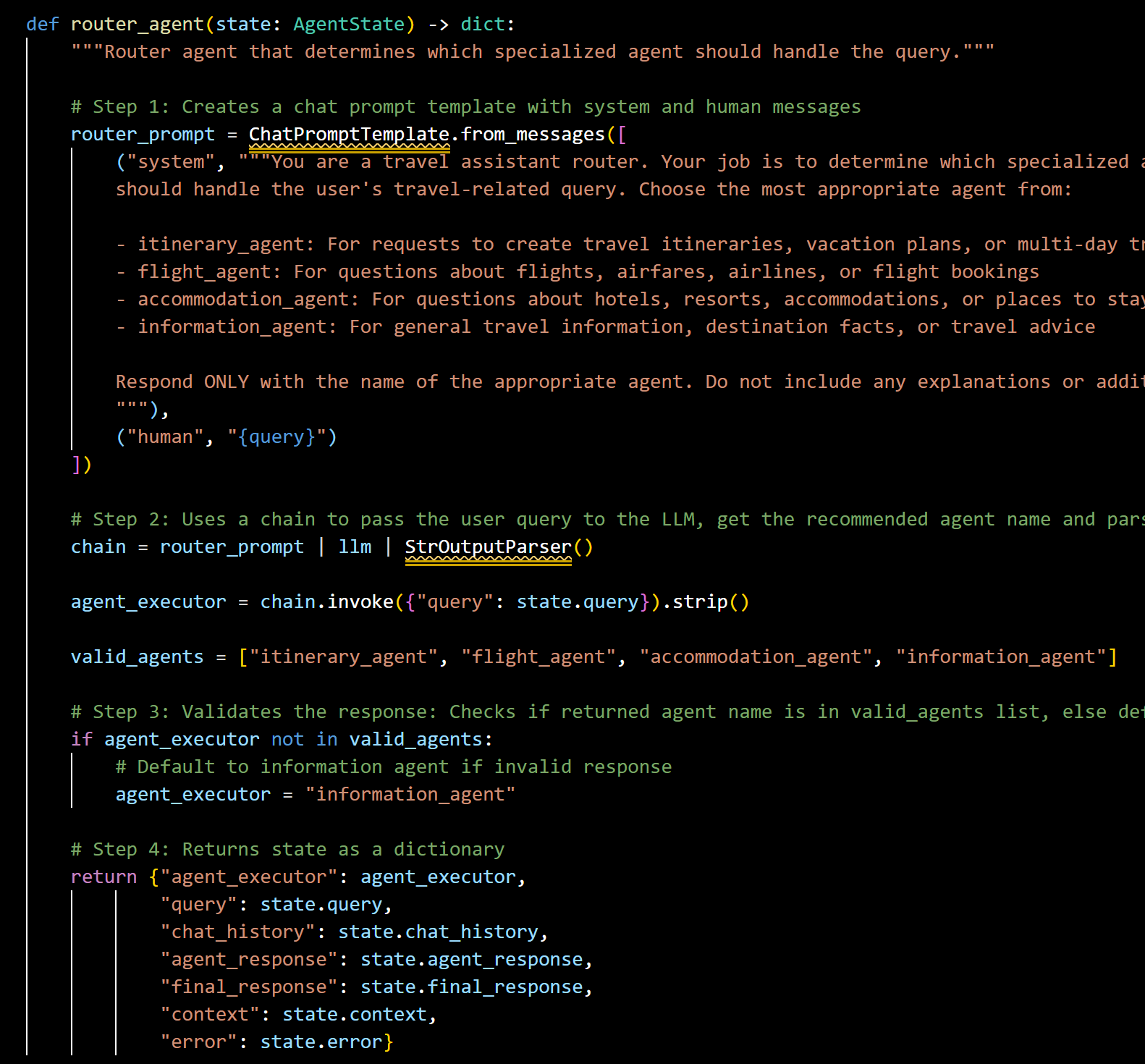 Snapshot of Router State
Snapshot of Router State
The router agent’s design follows a three-step process of query analysis by using a specialized prompt, query mapping to one of the four agent categories, and validation of agent selection. This approach allows for accurate routing of user queries.
3.1.3 Specialized Agents Implementation
The next-gen AI travel assistant is structured around four specialized agents, each designed to handle specific types of travel queries using tailored prompting strategies and information retrieval approaches.
- These agents work collaboratively using LangGraph to ensure a seamless, data-driven, and highly personalized itinerary-building process.
- These four agents work in sync within the multi-agent RAG architecture, ensuring travellers receive accurate, contextual, and unbiased travel planning assistance while reducing decision fatigue.
(A) Itinerary Agent: Personalized Travel Planning
This agent curates a personalized travel itinerary by optimizing sightseeing, activities, and experiences based on user preferences, real-time weather, crowd density, and travel feasibility. It ensures that users get a well-balanced plan that maximizes their time while considering FOMO-inducing experiences. It implements a sophisticated multi-stage process:
- Information Retrieval: Uses RAG to gather relevant destination data
- Parameter Extraction: Identifies key travel parameters (destinations, duration, budget, etc.)
- Itinerary Generation: Creates a day-by-day plan based on the extracted parameters and retrieved information
- Error Handling: Gracefully manages parsing errors and missing information
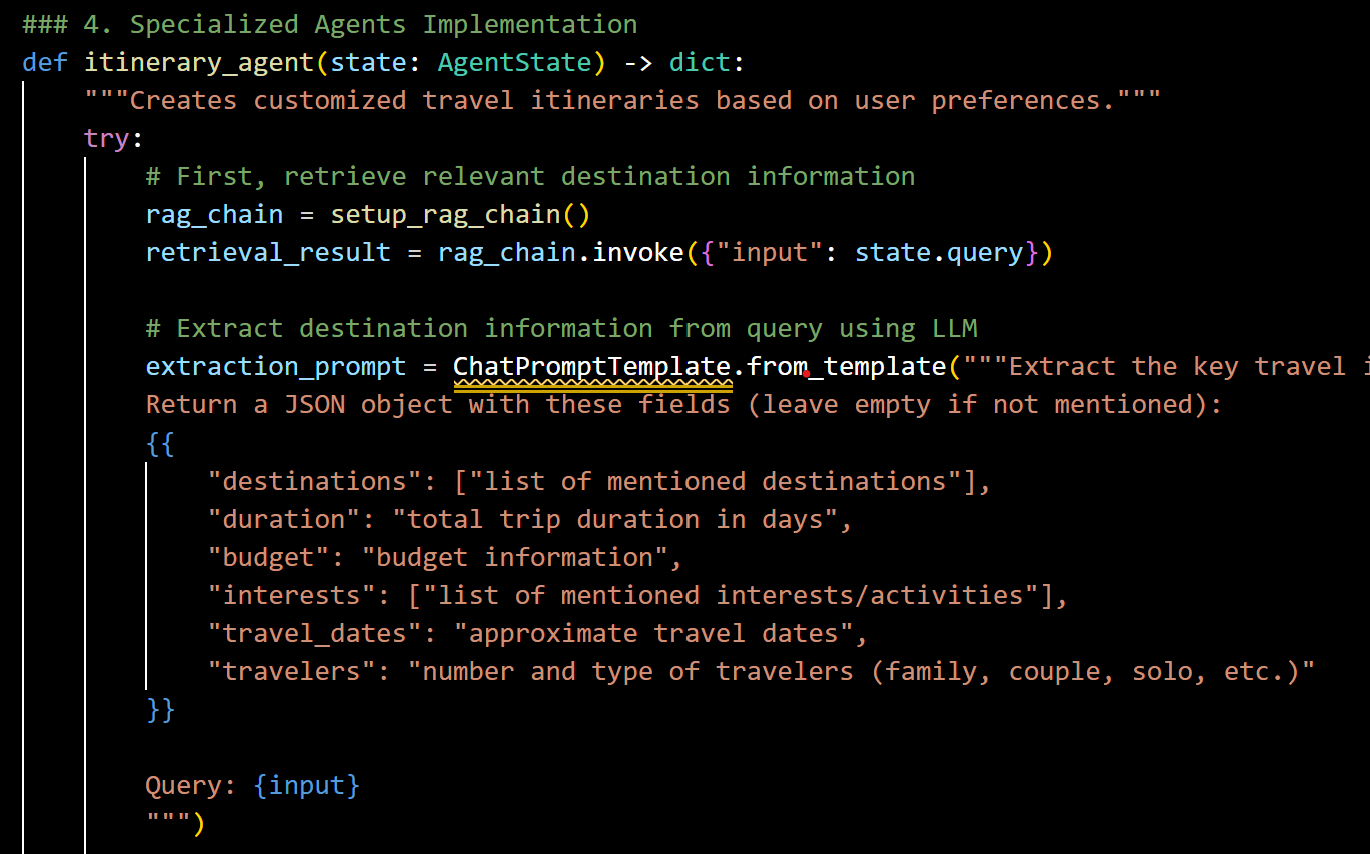 Snapshot of Itinerary Agent
Snapshot of Itinerary Agent
This approach enables the creation of realistic, detailed itineraries that account for practical constraints like travel times between attractions and local customs. The JSON-based parameter extraction allows for structured representation of user preferences that can be used for consistent planning across different destinations.
(B) Flight Agent: Comprehensive Flight Analysis
The flight agent searches and compares flight options from multiple airlines and aggregators, considering factors like pricing trends, layovers, baggage policies, and hidden costs. It helps users find the most cost-effective and convenient flight options based on their travel dates and preferences. The flight agent follows a structured workflow:
- Parameter Extraction: Identifies key flight search criteria from natural language
- Context Building: Maintains extracted parameters in the conversation state
- Information Retrieval: Uses RAG to find relevant flight data
- Response Generation: Creates a comprehensive analysis including options, prices, and booking advice
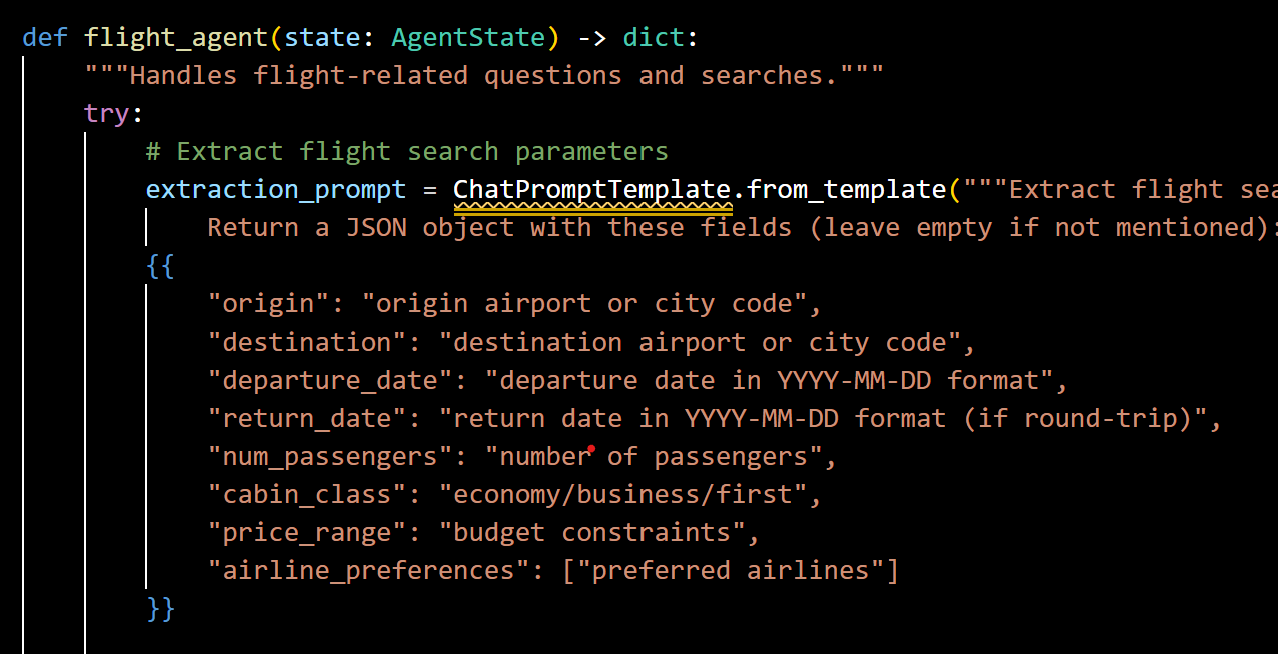 Snapshot of Flight Agent
Snapshot of Flight Agent
This agent demonstrates the power of structured parameter extraction combined with knowledge retrieval, enabling detailed flight recommendations even when specific flight data might be incomplete in the knowledge base.
(C) Accommodation Agent: Hotel availability
The accommodation agent is responsible for retrieving and recommending hotels, hostels, or vacation rentals that fit the user’s budget, preferences, and proximity to key attractions. It prioritizes unbiased, data-driven suggestions over vendor-sponsored listings, ensuring travellers get the best value for their stay. The accommodation agent implements:
- Preference Extraction: Identifies key accommodation parameters
- Location-Based Retrieval: Performs targeted RAG queries based on the extracted location
- Contextualized Recommendations: Generates hotel suggestions with rich location context
- Practical Details: Includes information on amenities, pricing, and booking strategies
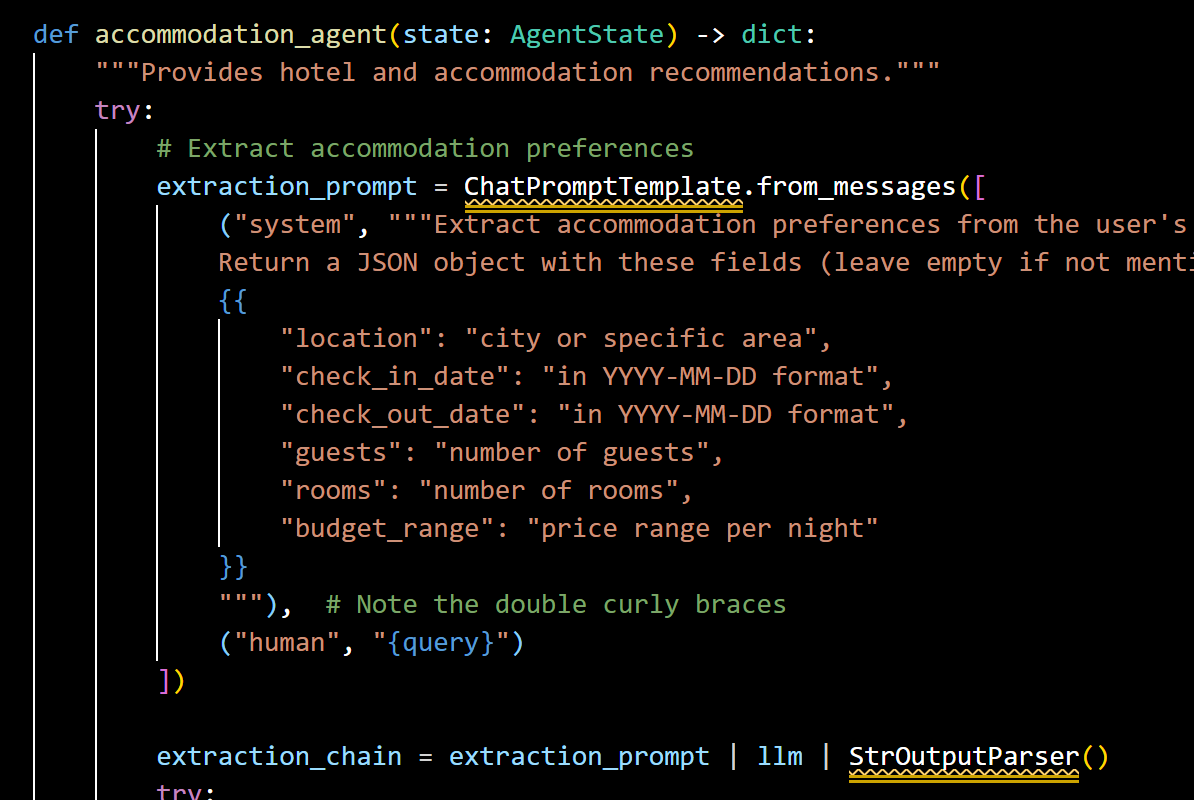 Snapshot of Accommodation Agent
Snapshot of Accommodation Agent
This agent shows how specific parameter extraction combined with the rich knowledge base can provide highly contextualized accommodation recommendations that go beyond simple listings to include neighborhood information and practical advice.
(D) Information Agent: Travel-related knowledge
The information agent gathers and synthesizes relevant travel advisory data, including visa requirements, local safety updates, cultural norms, and real-time conditions like weather, footfall density, and local events. This agent ensures travellers have a realistic expectation of their destination. It utilizes:
- RAG: Retrieves relevant information from the knowledge base
- Response Enhancement: Enriches the retrieved information with additional context
- Practical Focus: Emphasizes actionable insights and traveller tips
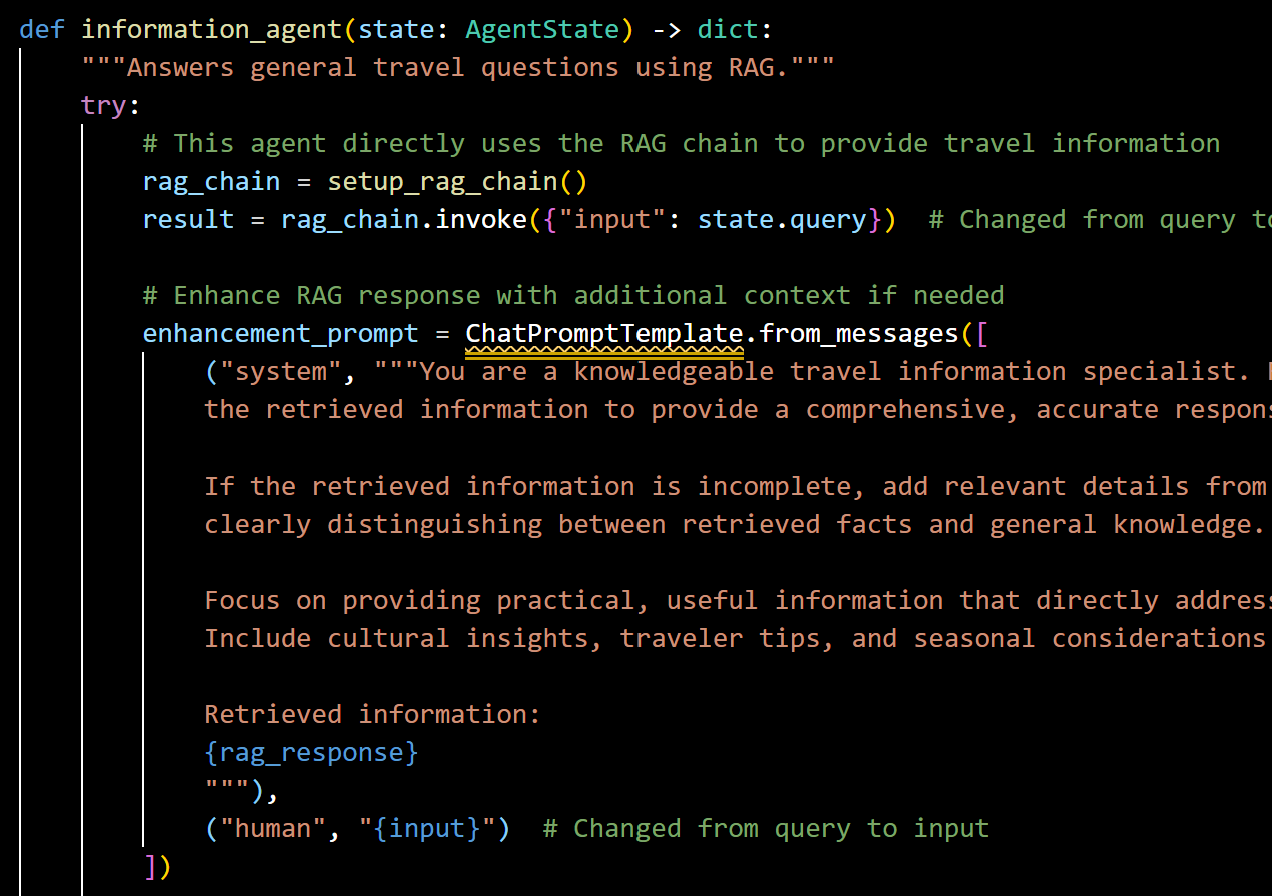 Snapshot of Information Agent
Snapshot of Information Agent
This agent demonstrates the value of a two-stage approach to RAG, where the initial retrieval is enhanced with additional processing to create more comprehensive and useful responses.
3.2 RAG Integration and Knowledge Retrieval
The system integrates the vector knowledge base created during the data preparation step through a standardized RAG chain.
This implementation features several key design choices which we :
- Similarity Search: Uses vector similarity to find relevant documents
- Multiple Document Retrieval: Retrieves 7 documents to ensure comprehensive coverage
- Document Combination: Uses the “stuff” method to combine documents into a single context
- Balanced Prompting: Instructs the model to prioritize retrieved information while allowing for knowledge augmentation
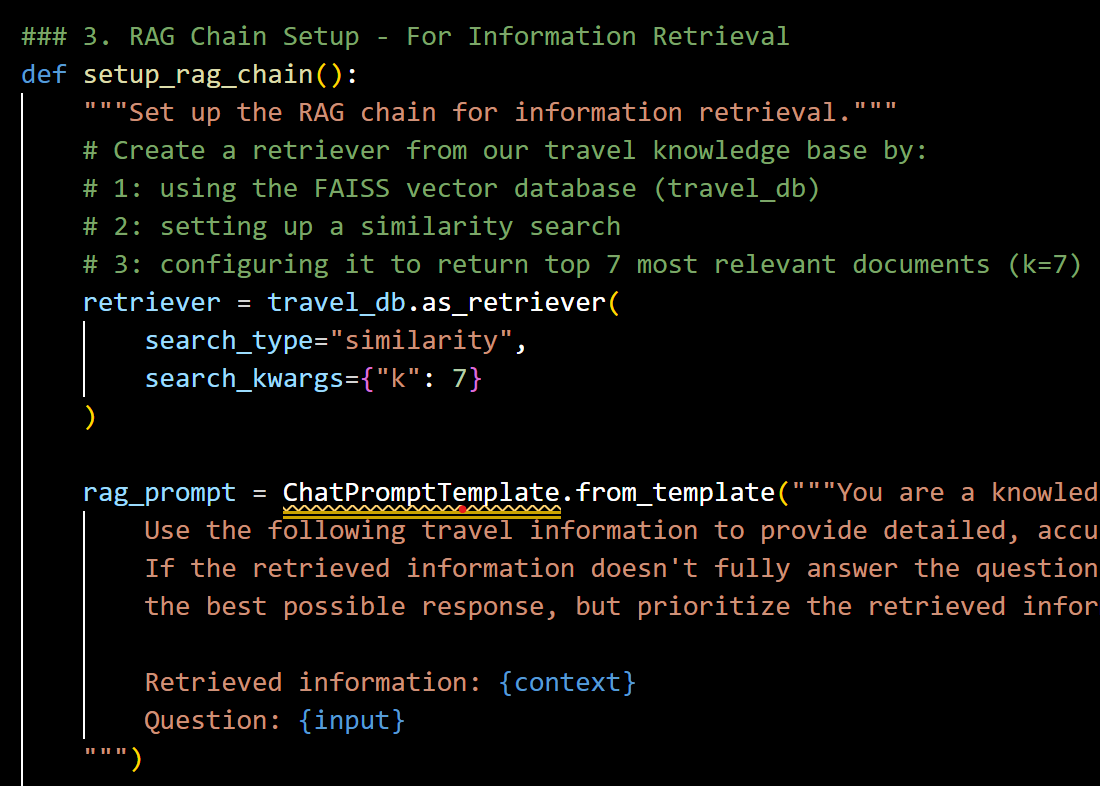 Snapshot of RAG chain
Snapshot of RAG chain
This approach balances the factual precision of retrieved information with the general knowledge capabilities of the language model, creating responses that are both accurate and comprehensive.
3.3 Response Generation and Error Handling
The system includes dedicated components for response formatting and error handling to ensure a consistent, high-quality user experience.
3.3.1 Response Generator
The response generator transforms raw agent outputs into user-friendly, well-structured responses by structural enhancement (by adding headings, bullet points), visual elements (incorporating appropriate formatting), and conversational cues. This component ensures that all responses, regardless of which agent generated them, maintain a consistent, engaging style that enhances readability and user experience.
3.3.2 Error Handler
The error handler provides recovery from system errors by acknowledgment of the issue, fallback information (providing general advice related to the query), user guidance regarding query reformulation, and continuity preservation maintaining the conversation flow despite the errors.
This approach ensures that the system remains useful and responsive even when errors occur, contributing to a robust user experience.
The directed graph architecture allows for complex workflow design while maintaining clean separation of concerns between the different system components.
3.4 System Performance and Evaluation
At the end of the notebook, I conduct vibe checking to test the tool and evaluate the performance of each specialized agent and few edge cases. These tests verify the capabilities of the system to handle a diverse range of travel queries such as correct agent classification (query routing), parameter extraction (accurate identification of key parameters from natural language / unstructured data), knowledge retrieval (effective use of the RAG system to find relevant information), and response quality (generation of comprehensive, useful travel advice).
3.5 Agent System Architecture Advantages
The multi-agent architecture offers several significant advantages for travel planning applications:
1. Specificity of expertise: Each agent focuses on a specific aspect of travel planning (itinerary / accommodation / flight / information), allowing for deeper domain knowledge and more targeted responses.
2. Modular design: This makes it easy to add, remove, or modify agents, perform unit testing, and overall system testing without disrupting the overall system.
3. Contextual Awareness: The shared state model allows agents to build on each other’s work and maintain conversation context across multiple turns.
3.6 Future Enhancements for the Agent System
Several potential enhancements could further improve the agent system:
1. Expanded Testing and Expert-driven Evaluation: Creating a more extensive evaluation framework for deeper assessment of quality of agent responses and, embed HITL (human-in-the-loop) feedback.
2. Multi-Agent Collaboration: Enabling collaboration between specialized agents on complex queries that span multiple domains (e.g., an itinerary that includes flight and accommodation recommendations).
3. Hybrid Routing: Integrating the worlds of tradtional AI and GenAI by using a ML classifier for agent selection, combining embedding-based similarity with explicit classification.
4. Experimenting with design choices of RAG, LLMs: Trying out different possible choices for parameters of RAG such as similarity search, parameters of LLMs, and choice of LLMs to identify where the system performance optimizes across the most important metrics.
4. Generating test set for evaluation
I, next, deploy the application to Hugging Face and start evaluation of the assistant built. In the next steps, I work on generating a synthetic data set for testing the application and evaluate it using RAGAS (Retrieval Augmented Generation Assessment), a framework for evaluating RAG systems.
The key component is the generate_comprehensive_test_set function, which creates a diverse set of test scenarios for evaluating different aspects of the travel assistant.
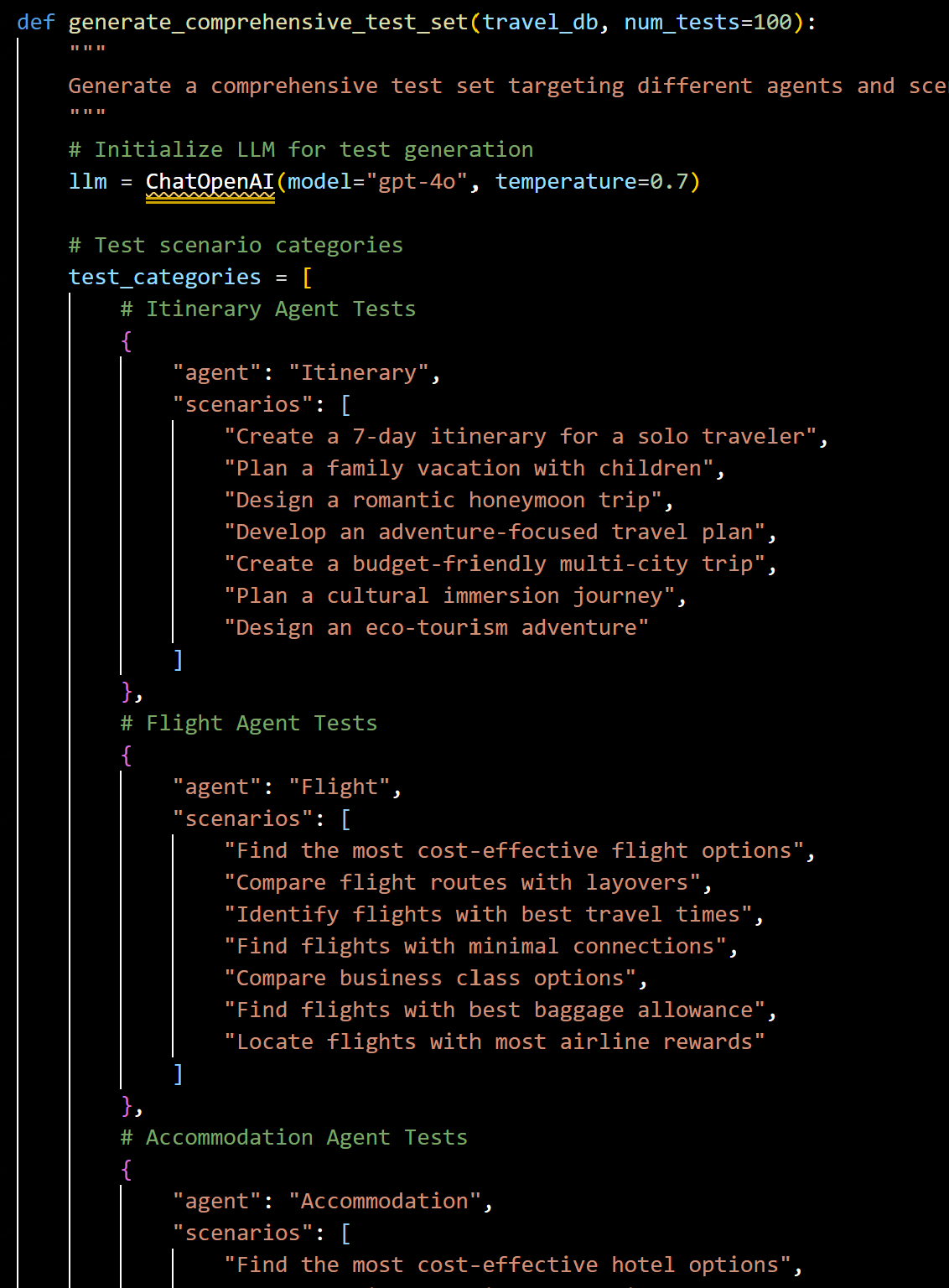 Snapshot of test set generation step
Snapshot of test set generation step
The test generation is structured around the four key agents of Travel AI system - flight, accommodation, itinerary, and information.
For each agent type, I define a range of varying scenarios to test, creating a matrix of test cases. For example, the Itinerary Agent is tested on scenarios like solo travel planning, family vacations, and honeymoon trips.
4.1 Key components
4.1.1 LLM-based Test Set Generation
- The central component is the generate_comprehensive_test_set function, which creates a diverse set of test scenarios for evaluating different aspects of the travel assistant. For each agent type, the code defines multiple scenarios to test, creating a matrix of test cases. For example, the Itinerary Agent is tested on scenarios like solo travel planning, family vacations, and honeymoon trips.
- The function employs GPT-4o to generate contextually relevant questions. This approach intelligently leverages an LLM to create challenging test cases rather than using fixed, predefined questions. The system extracts actual travel knowledge contexts from the RAG’s document store, which ensures that the test cases are aligned with the knowledge the system is expected to have.
- For each test question, the code also generates reference answers. These reference answers serve as a gold standard for evaluating the travel assistant’s responses.
4.1.2 RAGAS evaluation
While I use RAGAS to assess the system, running the evaluation to test each agent provides deeper insights such as the following.
- Low Faithfulness: The faithfulness scores are consistently low across all agents, suggesting potential hallucination issues where the system may generate content not strictly supported by the context.
- Unstable Answer Relevancy across agents: Accommodation agent shows dramatically lower answer relevancy (0.1466) compared to other agents, indicating possible conceptual gaps in addressing accommodation-related queries.
- Strong Context Precision: All agents demonstrate good context precision (0.8000+), suggesting they generally use relevant information from the context.
- Agent Performance Disparity: The Itinerary agent performs best overall with highest scores in relevancy, precision, and recall, while the Accommodation agent struggles with relevancy despite good precision and recall scores.
While I have tried to do extensive error handling and save all results, the code execution is computationally intensive.
4.3 Future enhancements
- Increase size of test dataset: Currently, I generate only 100 test data samples but it would be beneficial to test the system on a larger dataset to derive more insights by examining the system responses on a larger and wider scale of queries.
- Faithfulness Enhancement: The extremely low faithfulness scores suggests the urgent need to improve the RAG system’s grounding in source material.
- Accommodation Agent Remediation: The accommodation agent’s poor answer relevancy requires targeted improvement, possibly through better context retrieval or response generation.
- LLM Configuration: The evaluation uses GPT-4-turbo and GPT-4o with temperature=0.7, which might introduce variability. A lower temperature setting could potentially improve consistency.
- Test Set Balance: While the code validates that all four agents are represented, it doesn’t explicitly ensure equal representation.
5. Fine-tuning embedding model
In this module, I experiment with fine-tuning of embedding models to understand if it can enhance the performance of Travel AI system by adapting pre-trained embeddings to specialized domains. For this, I use the following steps:
(1) Data structuring: The workflow begins by loading documents from a FAISS vector store that contains ~5k~ travel-related documents. These were indexed previously by using OpenAI embeddings. Since these documents form the custom training data for fine-tuning an embedding model, metadaat associated with them and important categorical fields are also extracted. They are used to determine document similarity. The system intelligently filters for metadata fields that offer meaningful differentiation - common enough to appear across multiple documents but specific enough to create meaningful distinctions.
(2) Creating Semantic Pairings for Training: Training data preparation relies on creating document pairs with appropriate similarity scores. Here I try to
- identify pairs of documents that share similar metadata attributes (positive pairs),
- create document pairs with minimal metadata overlap (negative pairs), and
- assign similarity scores based on metadata overlap percentages
This approach resulted in 2,110 training pairs, split into 1,688 training and 422 validation examples - fewer than the target but sufficient for fine-tuning.
(3) Implementing Matryoshka Embeddings: Using Matryoshka embeddings enables creating embeddings of multiple dimensionalities from a single model. I run these experiments for an array of matryoshka dimensions [384, 256, 128, 64], creating a flexible embedding model that can produce representations at various granularities from the same forward pass.
(4) Fine-Tuning Process: I run the fine-tuning process using the SentenceTransformer framework with the “all-MiniLM-L6-v2” base model. The training configuration uses 10 training epochs, batch size of 16, 1000 evaluation steps, and CosineSimilarityLoss combined with MatryoshkaLoss as the loss function. This fine-tuning process takes ~2-2.5 hours to run, indicating the need to optimize the computational requirements of embedding model.
(5) Custom Embedding Class Implementation: To make the fine-tuned model practical for deployment, I implement a custom TravelAssistantEmbeddings class that provides an interface for document and query embedding. This class encapsulates the model’s functionality, making it easily integratable with LangChain and other RAG frameworks.
(6) Model Evaluation and Deployment: I perform comprehensive model testing, evaluate embedding quality with test queries, compute similarity matrices to assess semantic relationships, and save and load the model using HuggingFace’s infrastructure.
6. Evaluating impact of fine-tuned embeddings on performance
(1) Custom Embedding Integration: The core of our enhancement is the FineTunedTravelEmbeddings class that wraps a domain-specific SentenceTransformer model. This LangChain-compatible class handles both document and query embedding.
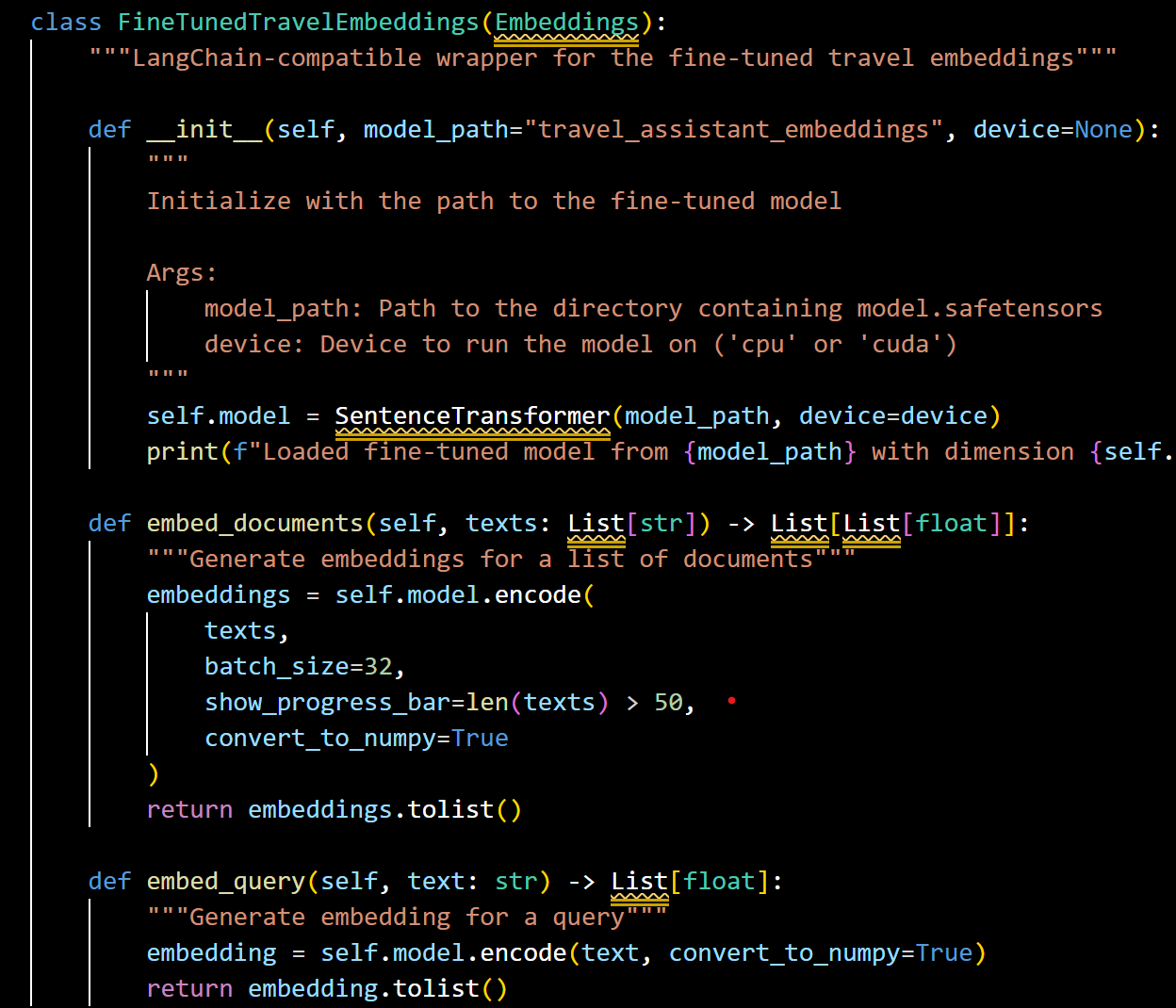 Snapshot of FineTunedTravelEmbeddings
Snapshot of FineTunedTravelEmbeddings
Document embedding is used during vector database creation to convert the travel documents into vector representations that capture travel-specific semantic meaning.
Query embedding is used to convert user queries into the same vector representation, enabling semantic similarity search to find the most relevant travel documents. By using fine-tuned embeddings, we have optimized the vector space for travel-specific language. For example, terms like “all-inclusive resort” and “beachfront accommodation” would be plotted closer together in the vector space as compared to their mapping in a general-purpose embedding model, improving retrieval relevance for travel queries.
(2) Vector Store Migration: Integrating a new embedding model requires rebuilding the vector store. Our implementation follows a two-step process:
- Extraction: Here, documents are retrieved from the existing vector store using the extract_documents_from_vector_store function, which carefully handles the FAISS index and document store relationships.
- Reindexing: The update_faiss_with_new_embeddings function creates a new vector store using our fine-tuned embeddings, preserving document content while updating the vector representations.
(3) Enhanced RAG Chain Architecture: The setup_rag_chain_fine_tuned function configures a retrieval-augmented generation chain with our domain-specific embeddings:
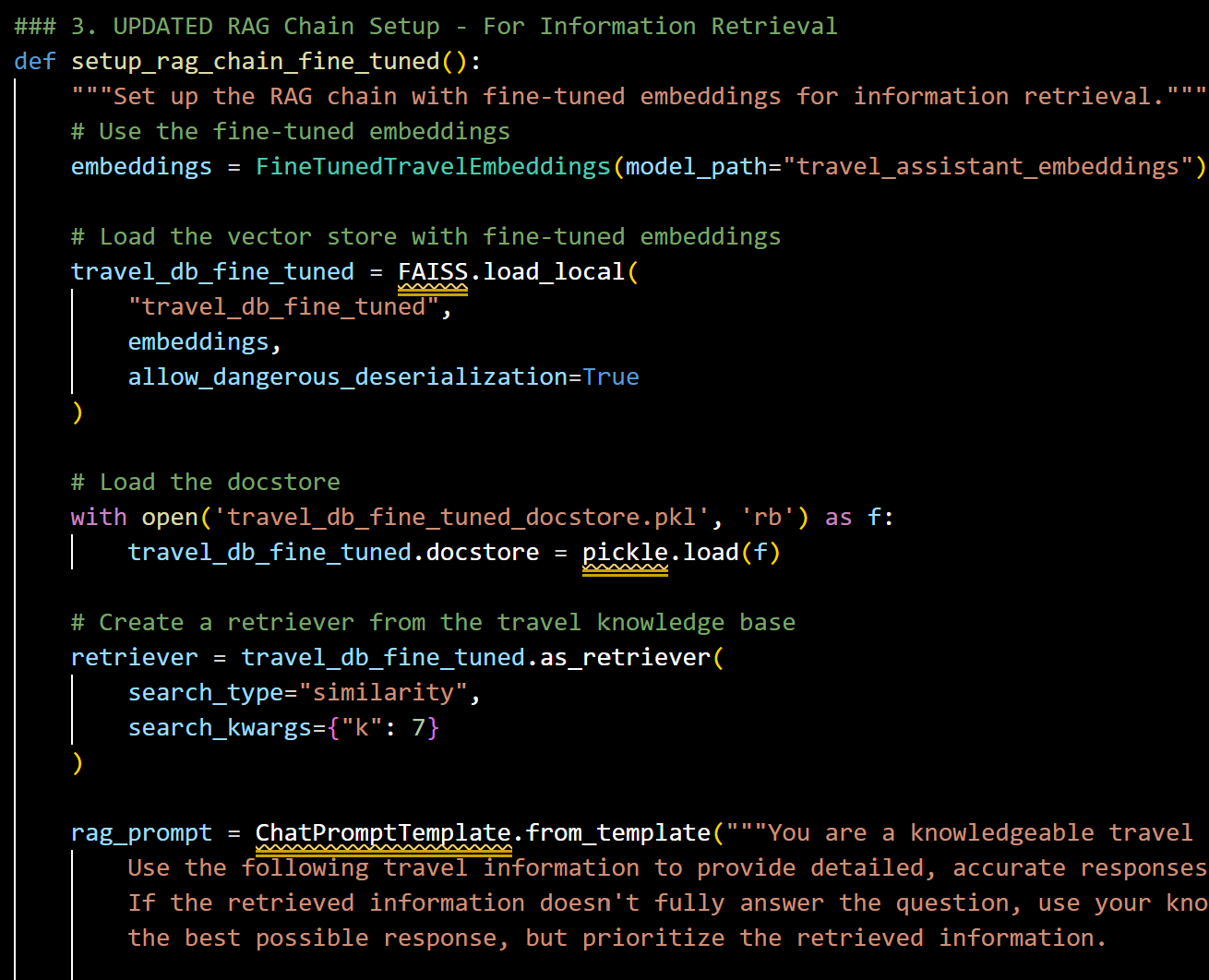 Snapshot of Fine Tuned RAG Chain
Snapshot of Fine Tuned RAG Chain
(4) Agent update with Fine-Tuned Context: Each sub-agent (itinerary, flight, accommodation, information) now leverages the domain-specific, fine-tuned embeddings for more contextually relevant information retrieval.
- Information Agent: Directly uses the fine-tuned RAG chain to answer general travel queries with enhanced retrieval of destination facts.
- Accommodation Agent: Extracts structured preferences via JSON, then uses fine-tuned embeddings to find contextually appropriate lodging information.
- Flight Agent: Combines structured flight parameter extraction with domain-optimized retrieval to provide relevant flight details.
- Itinerary Agent: Builds comprehensive travel plans by leveraging the improved semantic matching of destinations, activities, and points of interest.
(5) Workflow Orchestration: The agent workflow is managed through a directed graph using LangGraph, with specialized routing based on query classification.
(6) Performance Evaluation: The fine-tuned system is evaluated using RAGAS metrics across different query types, revealing significant improvements in context recall and answer relevancy compared to earlier model using generic embeddings. While faithfulness scores remain an area for improvement, context precision showed consistent high performance across all agent types, particularly for itinerary planning (0.86) and general information queries (0.85). This fine-tuned embedding approach demonstrates how domain-specific vector representations can enhance RAG systems in specialized domains like travel, creating more contextually aware multi-agent systems that better understand the semantic relationships in their knowledge domain.
7. Next Steps
Key guiding factor for next set of sprints is to take this Travel AI system from prototype to production. This requires several strategic engineering initiatives.
The vector store infrastructure needs migration to a distributed vector database like Pinecone, Weaviate, or Qdrant to ensure horizontal scalability and real-time updates. This would replace the current FAISS implementation while maintaining compatibility with our fine-tuned embeddings.
Second, agent orchestration should be refactored into a microservices architecture, with each specialized agent deployed as an independent service with defined API contracts, enabling independent scaling based on query patterns (e.g., scaling up the accommodation agent during peak booking seasons).
For reliability, implementing robust monitoring is essential—tracking metrics like retrieval precision, token usage, and response latency while establishing SLAs for each agent type.
Experiment with the various levers identified and documented in each module as opportunities to improve results.
Security considerations demand proper authentication, rate limiting, and PII handling to protect sensitive user data like travel dates and preferences.
Finally, cost optimization requires strategic caching of common queries, right-sizing embedding models, and implementing tiered retrieval that balances semantic search quality against computational expense.
These enhancements would transform the current RAG-powered prototype into an enterprise-grade travel intelligence platform capable of handling thousands of concurrent users while delivering personalized, contextually-aware,and accurate responses.
APPENDIX
Complete Source Code: Git repo of Travel AI
| Module | Notebook location |
|---|---|
| 1: Wall of imports | https://github.com/deeptidabral/AIE5/blob/main/Mid-Term%20Project/00_wall_of_imports.ipynb |
| 2: Data sourcing | https://github.com/deeptidabral/AIE5/blob/main/Mid-Term%20Project/01_data_pipeline_creation.ipynb |
| 3: RAG and Multi-agent set-up | https://github.com/deeptidabral/AIE5/blob/main/Mid-Term%20Project/02_agent_setup.ipynb |
| 4: Test set generation and RAGAS assessment | https://github.com/deeptidabral/AIE5/blob/main/Mid-Term%20Project/03_testset_generation.ipynb |
| 5: Fine-tuning embedding | https://github.com/deeptidabral/AIE5/blob/main/Mid-Term%20Project/04_fine_tuning_embedding.ipynb |
| 6: Agent update with fine-tuned embedding | https://github.com/deeptidabral/AIE5/blob/main/Mid-Term%20Project/05_agent_rerun_with_fine_tuned_embedding.ipynb |