
Leveraging Synthetic Data in Agentic AI
In this blog, I will be exploring the transformative impact of synthetic data generation (SDG) in AI development, particularly focusing on its critical importance for agentic AI systems. It comprehensively explores how synthetic data can enhance AI agent training through diverse simulated interactions, multimodal understanding, and robust error handling capabilities. The write-up culminates with practical implementation guidance, including a detailed example using the RAGAS library to generate and evaluate synthetic data for Retrieval Augmented Generation (RAG) systems, demonstrating how we can leverage synthetic data to build more reliable and capable AI agents.
1. Overview of Synthetic Data
1.1 What is synthetic data?
Synthetic data is artificial but realistic data generated to increase the availability of data required for critical stages of the AI/ML model lifecycle where the use case might not have sufficient data samples. It is critical to note that even though synthetic data is completely fake, it is representative of real-world data, thus, making it usable for AI model training, testing, supervised fine-tuning, and governance purposes. Synthetic data generation (SDG) creates new data points / samples mimicking the real-world data variables and data samples.
1.2 When is it needed?
Synthetic data is needed when actual data is either or all the following:
- Limited (in availability) – Real data can be scarce or difficult to source. Synthetic data can be generated to simulate uncommon or rare events, edge cases, and complex scenarios to ensure meaningful modeling efforts.
- Sensitive and confidential – AI use cases from sectors such as healthcare industry may have access to sensitive data fields identifying patients (PII) and their medical history. Synthetic data does not suffer from privacy concerns.
- Biased – Existing data can be biased, and imbalanced, thus, not representative of various population groups (e.g., customer segments, transaction categories, business types, etc.) or subgroups. If understanding the behavior of these groups or subgroups is critical to the AI application, then the real data would not be sufficient to ensure fairness in AI models built using it.
- Expensive – Collecting real data (e.g., via surveys) can be expensive, hugely manual, and time-consuming and yet, fall short of the target data volume needed for all efforts. On the other hand, synthetic data can generate data at scale and be used across the AI product lifecycle across development, testing, production, and maintenance.
1.3 What are the leading benefits of synthetic data?
Good quality synthetic data has several benefits such as the following -
- Provisioning of data-at-scale: It provides realistic and safe data at scale. This can be used for training, testing, and validating AI models and applications during development. Additionally, as concept drifts emerge in data while AI models are in production, synthetic data can be generated for evolving data distributions to ensure ongoing testing and retraining of models. Therefore, synthetic data has high utility throughout the lifecycle of AI products and enables scalable testing environments for organizations.
- Handling bias in data: Real-world data may suffer from biases, and inaccuracies. Synthetic data, curated to introduce diversity, removes bias from existing datasets and enables extensive testing of a wide variety of potential vulnerabilities and points of failure in AI models / applications. The synthetic data samples can be used to balance naturally occurring imbalanced datasets by oversampling underrepresented classes.
- Scalable and seamless model testing: Specialized testing of AI models, focused on specific business objectives, can be done. To ensure sufficient adversarial testing of AI models, synthetic data can come in handy, if original datasets are lacking edge case scenarios.
- Adherence to data privacy and regulations: Since synthetic data is fake, this new data generated is never non-compliant with data protection regulations such as GDPR (EU), CCPA (US), HIPAA (US), PIPEDA (Canada), and more, making its usage safe and secure.
- Maintaining data privacy: Since synthetic data records created are fully anonymous, they do not preserve any direct mapping or linkages to real business entities (e.g., customers, orders, transactions, etc.). It can be seamlessly shared across user roles and teams and used for collaboration without significant concerns about data safety.
1.4 Types of synthetic data
Synthetic data can be broadly categorized across two key dimensions.
(a) Generation technique
| Synthetic Data Type | Description | Challenges |
|---|---|---|
| Mock data | Generated based on a rules engine with predefined rules, constraints, and parameters (e.g., generate mock data for rules such as ‘loyal’ shoppers of a retailer purchasing at least n times and spending > $X in a week; ‘high risk’ customer segment of a credit card provider with >n open credit lines and frequent defaults in the past). | May resemble real data in structure but may not representative of rich patterns (e.g., volatility, multi-dimensional relationships, rare events) of actual data. Rules can become complex in business situations making syynthetic data generation compliant with them difficult to implement. |
| AI-generated synthetic data | Generated algorithmically using existing data samples as seed. Created by deep generative algorithms such as GPTs, GANs, VAEs, and more. | Dependent on availability of large enough samples to seed the data generation exercise. Risk of overfitting during generation making it a biased sample and unrepresentative of real-world data. Determining optimal synthetic data generators for specific datasets / use case / business context. Balancing the bias- variance tradeoff. |
(b) Modality
| Synthetic Data Type | Description | Challenges |
|---|---|---|
| Structured synthetic data | Fictitious, life-like data which mimics the structural characteristics (statistical distributions) and properties of real data. Created using statistical modelling to simulate data that closely resembles the original data in terms of its statistical properties, and relationships between variables. | High probability of error propagation and bias amplification, if actual underlying data suffers from inherent biases and unidentified errors. |
| Unstructured synthetic data | Fake data in free-form modalities such as images, videos, text, and audio. Created by deep generative algorithms such as LLMs, Diffusion models, GANs, and more. Generation of text that closely mirrors human language, LLMs facilitate the creation of robust, varied datasets necessary for training and refining AI models across various applications. | May lack subtle details and relationships across data variables and samples present in real data. Sophisticated validation of the synthetic data can be quite complex and require deep expertise in unstructured data. |
2. Generative AI Techniques for SDG
2.1 How can GenAI be used for synthetic data generation?
A variety of deep learning models such as GANs, VAEs, Diffusion Models, and LLMs can be used to create realistic structured (tabular), unstructured (text, images, audio), or multimodal datasets.
| S.No. | Data Modality | GenAI Models / Algorithms | Illustrative Data Generated | Popular Use Cases | Potential Challenges / Limitations |
|---|---|---|---|---|---|
| 1 | Tabular Data (Structured Data) | Bayesian Networks, GANs (e.g., CTGAN, Tabular GAN), TimeGAN for sequential data, Autoencoders for anomaly detection | Financial, healthcare, or business datasets. Customer behavior (account balance, product holding). | Up-sell / Cross-sell, hyper-personalization, NPTB / recommender systems, churn prediction, credit risk underwriting, data augmentation for imbalanced datasets | Maintaining relational integrity rules of actual data (in relational databases). Privacy concerns (re-identification risks). Bias in generated datasets. |
| 2 | Text | Prompt engineering with LLMs (e.g., GPT, BERT, T5, LLaMA), Retrieval-Augmented Generation (RAG), Knowledge Graphs for text consistency | Customer conversation and feedback data | Chatbot training, sentiment analysis, and text summarization, fake news detection | Hallucination issues in LLMs. Ensuring fact-checking and logical consistency. Bias in generated text. |
| 3 | Image (CV) | Latent space interpolation in GANs, CLIP-guided image synthesis, Style transfer for dataset expansion; GANs (e.g., StyleGAN, BigGAN) and Diffusion Models (e.g., Stable Diffusion) | Human faces, medical images (MRI, X-rays), product images for online commerce, rare object detection datasets | Facial recognition, medical imaging (anonymization & augmentation), self-driving car training, deepfake detection | Artifacts in GAN-based images. Ethical concerns (deepfakes). Ensuring medical image fidelity. |
| 4 | Audio & Speech | Text-to-Speech (TTS) and Voice Cloning models (e.g., WaveNet) | Speech samples, conversations of virtual assistants | Automatic speech recognition (ASR), voice assistants, AI-generated audiobooks, voice cloning | Synthetic speech sounding unnatural, Difficulty in capturing emotions accurately |
| 5 | Time-series Data | Recurrent Neural Networks (RNNs), Transformers, and GANs | Financial market data, sensor readings, and IoT device logs | Commodity price forecasting, algorithmic trading | Handling concept drift in long-term data |
3. Benefits of Synthetic Data for Agentic AI
3.1 How can synthetic data be used to augment agentic AI?
| S.No. | Use Case | Description | Example | GenAI Algorithms | Challenges & Limitations | Mitigation Strategies |
|---|---|---|---|---|---|---|
| 1 | Simulating User Interactions for Fine-Tuning | Improve training by introducing diversity in simulated conversations, user queries, and behavioral patterns. | Simulating customer-agent conversations to resolve customer concerns and consultation responses. | LLMs (e.g., GPT, Claude, LLaMA), Retrieval-Augmented Generation (RAG), Few-shot prompting | Risk of model overfitting to synthetic (fake) interactions. Ensuring realism in generated conversations. | Using human-in-the-loop (HITL) validation. Implementing hybrid strategy for model training with real and synthetic dialogues. |
| 2 | Enhancing Multimodal Agents | Synthetic multimodal (text, image, audio) data enables AI agents to understand and process multi-sensory inputs. | Generating synthetic voice commands for a voice assistant to improve speech recognition in noisy environments. | CLIP for text-image understanding, Speech2Text models (e.g., Whisper, Wav2Vec), Multimodal transformers. | Difficulties in aligning synthetic multimodal data with real-world user interactions. | Fine-tuning multimodal agents with real-world sensor data and human feedback. |
| 3 | Training Agents for Task Generalization | Synthetic workflows can help fine-tune task execution and problem-solving capabilities across different contexts. | Creating synthetic task descriptions to train AI agents in handling rare or complex scenarios (e.g., legal contract drafting). | Self-supervised learning, Reinforcement Learning from Human Feedback (RLHF) | Ensuring synthetic workflows align with actual real-world task expectations. | Calibrating synthetic data distributions to match real-world datasets. Continuous domain adaptation. |
| 4 | Error Handling and Recovery Strategies | Synthetic failure scenarios help agents learn self-correction, automated recovery, and fallback strategies. | Simulating API failures for an autonomous trading bot to train it on recovery and exception-handling strategies. | Fine-tuned LLMs with synthetic failure dialogues. Policy gradient-based reinforcement learning. | Balancing failure simulations with real-world unpredictability. Avoiding false positives in error detection. | Using adversarial training to expose AI agents to a variety of failure scenarios. |
| 5 | Reinforcement Learning for AI Agents | Synthetic rewards, environments, or policies in reinforcement learning enable scalable AI training for decision-making. | Training an AI agent to optimize personalized readings based on simulated customer behavioral data and feedback. | Deep Q Networks (DQN). Curriculum learning for stepwise training | Overfitting to synthetic environments. Risk of unrealistic reward functions leading to suboptimal policies. | Combining synthetic training with real-world reinforcement environments. Reward function optimization. |
| 6 | Bias Reduction and Fairness Training | Generating diverse synthetic user profiles and interactions to mitigate bias in AI decision-making and recommendations. | Generating synthetic demographic data to train AI hiring bots to avoid biases in job recommendations. | Counterfactual data generation using GANs. Debiasing techniques in synthetic dataset curation. | Synthetic demographic data might not fully generalize to real-world diversity. Potential bias in data generation models. | Leveraging fairness-aware synthetic data curation methods. Regular audits for synthetic dataset biases. |
| 7 | Testing AI Agent Robustness and Security | Using adversarial synthetic data to test AI agents against edge cases, security threats, and adversarial attacks. | Introducing adversarial prompts to test AI chatbots for prompt injection attacks and misinformation resilience. | Adversarial AI techniques (e.g., adversarial perturbations, red-teaming AI), AI security stress testing frameworks. | Ensuring adversarial synthetic data does not create unintended vulnerabilities. Maintaining ethical AI boundaries. | Deploying adversarial robustness testing. Implementing real-world scenario benchmarking for AI resilience. |
3.2 What are the key impact levers of synthetic data in the evaluation of agents?
Synthetic data can enable agent evaluation in a robust and comprehensive way.
| S.No. | Dimension of Evaluation | Description (What will synthetic datasets test?) | What is being evaluated in agents? | Why this evaluation matters? | Illustrative Test Scenarios in context of a customer service chatbot in retail banking |
|---|---|---|---|---|---|
| 1 | Complex Problem Solving and Logical Reasoning | Test for logical capabilities, multi-step reasoning tasks, deductive, and inductive reasoning tasks. | Is the agent capable of performing step-by-step reasoning rather than simple pattern matching? Multi-step or abstract reasoning tasks? | Ensures agent is performing robust step-by-step reasoning. Identifies weaknesses in multi-step or abstract reasoning tasks. | Testing duplicate transaction disputes requiring the agent to look up and identify multiple identical charges, analyze account histories, verify merchant details. |
| 2 | Fact-checking and Correctness | Test for fake citations, claims, or facts inserted by synthetic data in responses. Measure overall reliability and accuracy. | Is the agent capable of retrieving high-relevance, accurate documents for a specific RAG system? Detecting fake claims or misinformation in synthetic datasets? | Reduces the risk of hallucination. Ensures grounded responses based on facts. | Testing chatbot for queries with well-known correct responses such as loan eligibility, credit limit increase, product-related explanations, and fee calculations. |
| 3 | Alignment with Human Intent (Ethics, Fairness, Bias Mitigation) | Test for toxic, biased, unethical responses using adversarial prompting. Measure responses across different cultural and socioeconomic populations. | Is the agent providing ethical, fair, and non-toxic responses to adversarial prompts? Ensuring compliance with ethical and regulatory standards? | Detects biases and toxicity against specific marginalized user groups. Ensures compliance with responsible AI principles. | Testing chatbot for consistency in service quality across income groups, demographics, and ethnic groups. |
| 4 | Usage of Toolset by Agents | Test if agents correctly use tools by generating datasets specifying actions requiring specific tool invocations. | Is the agent invoking the right tools for specific actions? E.g., ArvixQueryRun for research papers or Tavily Search API for online searches. | Tests decision-making flow of the agent to invoke the right tool for the job. Detects failure points when tools return unexpected results. | Testing chatbot’s ability to use core banking access (transaction history, product holding), fraud detection tools, human agent handoff tool, etc. |
| 5 | Data Drift Monitoring | Test for alerts/thresholds on model risk parameters, anomaly detection, and major data distribution changes. | Is the agent handling edge cases? Detecting data distribution shifts and model resilience against them? | Detects changing population patterns and updates models for adaptation. Manages concept drift. | Using time-series synthetic data to test for changes in customer behavior due to external factors (e.g., competition, economic shifts). |
| 6 | Real-time Performance (Latency) | Test response time under high-volume, complex user queries. | Is the agent capable of handling high query volumes per second? Managing failures when APIs are inaccessible? | Stress-tests agent for real-life edge scenarios with production constraints. | Using synthetic data to simulate high load requirements, resource-intensive queries, and complex conversations. |
| 7 | Safety, Adversarial Testing & Jailbreak Prevention | Test resilience against exploits such as malicious prompts. | Is the agent capable of identifying adversarial prompts (e.g., scam messages, phishing attempts)? Preventing PII leakage? | Ensures agent responses do not contain harmful or toxic results. Improves handling of adversarial attacks. | Using synthetic data to simulate scenarios like identity theft, social engineering attacks, and fraudulent transaction attempts. |
3.3 What are some effective strategies to leverage synthetic data to improve Agentic AI applications?
Synthetic data provides scalability in model training, model testing, fine-tuning, and governance by providing data samples at scale. The additional data samples, that should be carefully vetted and validated before usage, enables the following critical activities:
1. Model training by–
• Data Augmentation: Synthetic data expands limited training datasets with diverse synthetic samples, simulating variations of existing scenarios and complex interactions, generating edge cases / rare events, and balancing data distributions.
• Bias Reduction: Synthetic data can be used to balance underrepresented segments in training data.
2. Model Testing by –
• Robustness Testing: Synthetic data allows model evaluation for adversarial or unseen conditions, specific simulated user behavior to test the agents in synthetic real-world interactions.
• Edge Case Testing: Synthetic data allows to create rare or extreme scenarios to assess failure modes.
• Performance Benchmarking: Additional data samples allow for standardized evaluation across different test conditions and help build a detailed performance analysis.
3. Supervised fine-tuning by allowing for customization of datasets for specific requirements and use cases.
4. Model governance by –
• Transparency: Synthetic data generation allows for precise control and monitoring and therefore, curation and quality checking of synthetic samples created. It also allows tracking data lineage and usage of these samples for various experiments.
• Privacy-Preserving Training: Synthetic data has no PII and eliminates any reliance on sensitive real-world data.
4. Evaluation and Validation of Synthetic Data
4.1 What should be the leading tenets of evaluating synthetic data?
- Perceptual Assessment – This means evaluating how well synthetic text, images, audio, or video align with human perception and real-world semantics. Comparing statistical properties of real and synthetic data and determining if they follow same distribution patterns would help understand how far or close is synthetic data to real data. Some examples of such comparisons could be:
- Similarity between word frequency distributions of real-world chats of customer and customer service chatbots and synthetic samples created using them
- Similarity between color, and spatial distributions of real-world geo-spatial data and synthetic projections of the same
- Similarity between pitch and tone distributions of audio data of customer feedback and synthetic samples created from it
- Semantic Consistency Checking – This includes checking whether synthetic data maintains logical coherence, retains meaningful relationships present in underlying data, and demonstrates contextual accuracy across its content. Synthetic data should be coherent across modalities such as text-image / caption-content alignment.
- Task-Specific Performance Evaluation & Model Generalization – This includes assessing the performance and effectiveness of synthetic data in improving AI model performance. Comparing performance of models trained on synthetic data versus models trained on real data can help understand value of synthetic data. Model performance metrics would vary based on the nature of use case.
- Bias, Authenticity & Ethical Risks – This includes detecting potential sources of bias such as representation bias and contextual bias, finding hallucinations in synthetic text, and determining misinformation in synthetic datasets.
4.2 What are some leading techniques of validating synthetic data?
Techniques such as KL Divergence, cosine similarity of text embeddings can help determine similarity between real and synthetic distributions. Metrics such as BLEU score, and ROUGE score help benchmark coherence and logical consistency of synthetic text. Additionally, adversarial robustness testing can help detect weaknesses in synthetic data.
Validation methods should check for meaningful and logically consistent semantic properties for its intended applications. Contextual coherence and logical flow analysis using coherence scoring techniques, semantic similarity and embedding validation using vector space alignment and similarity of embeddings, and fact checking using retrieval-based fact verification systems and fact-checking APIs are some of the leading methods.
- For assessing task-specific performance using synthetic data, it is crucial to analyze use case specific performance metrics such as the following:
- NLP applications: text summarization, similarity metrics of embedding models, context precision, and context recall
- Computer vision applications: object detection metrics, image comprehension quality, facial recognition reliability
- Metrics for bias assessment such as diversity metrics (to determine representation of underrepresented groups), fairness audits by using bias detection tools and adversarial testing can help detect and remove bias from synthetic data.
From an implementation perspective, Synthetic Data Metrics (SDMetrics) is an example of a Python library for evaluating tabular synthetic data. This can be used for generating, evaluating, and improving synthetic data. SDMetrics is a suite of validation tools to assess the quality of synthetic data based on statistical similarity, fidelity, and utility compared to real-world datasets. This package includes modules to conduct distributional similarity tests, and privacy risk evaluations. It also supports custom metric creation, allowing domain-specific validations such as bias detection and fairness analysis. Evaluating unstructured synthetic data requires specialized perceptual and semantic validation techniques like CLIP for images or BERT embeddings for text.
4.3 What are the potential risks of using synthetic data?
Automation of synthetic data generation can introduce risks with increased bias, inconsistencies, poor generalization (overfitting on seed data), and data leakage. These risks can cause the AI agents to make inaccurate and harmful decisions or actions in the real world.
If using automated synthetic data generation for AI agents, we must be extremely cautious of the quality of synthetic data to be used for model training / testing since synthetic data directly impacts the behavior, operations, and overall quality of AI systems. These key risks are:
- Data quality issues:
- Inconsistent, incoherent, and unreliable data which can cause AI agents consuming these datasets suffer from high hallucinations. E.g., a fraud-detection AI agent trained mostly on synthetic transaction patterns (and not real-world fraud) may not be best equipped to detect fraudulent behavior.
- Lack of diversity: Synthetic data should mimic the input data but also introduce diversity for nuanced AI modelling. If development dataset is not varied enough, then the model would not be smart enough to generate appropriate responses for rare events or events related to underrepresented groups.
- Bias inheritance / amplification – Undetected or unfixed bias in seed data can lead to further perpetuation of bias in newly generated synthetic data impacting the model performance, quality of insights, discriminatory AI behavior, and unwanted implications on business.
- Lack of understanding of the real-world context if synthetic data used for agent training is not adequately representing real scenarios, edge cases, and other key cases.
- Data privacy risks due to weak controls (e.g., poor anonymization techniques) synthetic data may cause data leakages. E.g., a healthcare AI agent trained on synthetic medical data might leak patient identities if lacking proper anonymization logic.
- Adversarial Exploits and Vulnerabilities If not carefully inspected and treated, synthetic data can introduce adversarial weaknesses, making AI agent applications easy targets for external attacks. E.g., a fraud detection agent trained on synthetic transaction data might miss real-life emerging attack patterns, allowing financial fraud based on these new patterns to go undetected.
- Poor Performance in Real-World Applications or Failures in Production: If synthetic data does not accurately reflect the diversity of real-world scenarios, AI agents may fail when deployed. Overfitting synthetic patterns can result agents proving to be non-resilient in live environments. E.g., A legal assistant AI agent trained using synthetic legal cases might hallucinate and advise flawed legal arguments that fail in court.
- Risk of model collapse / curse of recursion – For models that have been iteratively trained on data generated by them, model quality eventually degrades due to loss of original data distributions and lack of real data for model building. However, this can be managed well by incorporating human expertise and careful data generation efforts.
- Inability to use generic evaluation strategy and metrics – Development and deployment of every use case require careful and customized evaluation of synthetic data used to ensure accurate real-world data representation, and meaningful model results. Validation of synthetic data can be quite complicated and time-consuming.
- Insufficiency of one-time synthetic data generation – With emerging data drifts and concept drifts, synthetic data needed for additional testing over different time periods would have to be regenerated to adequately mimic the evolving data distributions.
4.4 What are the tactical considerations when considering using synthetic data?
Synthetic data must be tailored to the AI agent’s use case, ensuring it accurately represents real-world scenarios. Rigorous validation is critical—use statistical tests, privacy safeguards, adversarial testing, and fairness audits to ensure trustworthiness. AI agents trained on synthetic data must be evaluated in real-world environments before deployment.
To ensure AI agents are trustworthy, unbiased, and effective, synthetic data must be:
- Customized synthetic data manufacturing for specific business goals: Custom-designed datasets should match the AI’s specific domain / industry sector, use case, custom business objectives, and real-world challenges. An example could be a conversational AI needing synthetic dialogues that are reflective of a specific, not commonly used linguistic styles or domain expertise and related technical jargon.
- Statistical Validation: Validation metrics should confirm that synthetic data resembles real-world distributions closely. Packages such as SDMetrics, Great Expectations, and Fairlearn can be used to these distribution-level checks and real-world correlations. Careful examination of each generation iteration is vital to ensure we are not introducing any new biases.
- Privacy-Preserving and Regulatory-Compliant: Differential privacy techniques can help prevent data leakage by using tools such as DiffPrivLib and ARX Anonymization to maintain privacy guarantees. Diligent, automated controls to ensure compliance with regulations such as GDPR, HIPAA, and AI Ethics standards can help streamline and simplify compliance requirements.
- Stress-Tested in Real-World Scenarios: AI agents require thorough investigation and testing in real-world scenarios before deployment in production environment. Implementing detailed adversarial testing can help assess vulnerabilities. Production-level failures can disrupt ongoing business operations while negatively impacting customer experience. Repeated failures like these can even lead to customer churn.
- Bias and Fairness-driven auditing: Synthetic data samples must be audited for biases before any kind of usage. E.g., a chatbot trained on synthetic dialogues should be tested to ensure it does not favor or discriminate against certain user groups.
5. SDG and Using Synthetic Data with an AI Agent (with a sample notebook)
We can use Ragas to generate synthetic data and understand what this process looks like.
Ragas is a Python library designed for generating and evaluating synthetic data specifically for Retrieval Augmented Generation (RAG) systems.
It leverages knowledge graph-based algorithms to generate diverse synthetic question-answer pairs. The library establishes the logic to explore documents and connect related content, helping users create questions of a wide variety and complexity levels. By using knowledge graphs for data generation, Ragas simplifies creation of complex queries.
Ragas allows uploading the synthetic samples generated and viewing them in a dashboard through app.ragas.io for accelerated examination and accepting or rejecting specific samples.
Ragas employs a sophisticated evolutionary generation paradigm to create diverse question types or datasets, including reasoning questions, conditional queries, and multi-context scenarios, in addition to simple, straightforward queries. This variety of questions is needed to effectively test the RAG systems.
The library provides a TestsetGenerator class that handles synthetic data creation. Users can define the distribution of query types using built-in synthesizers. As part of the Ragas library, ragas.testset.synthesizers is used for evaluating RAG systems. The provided synthesizers are used to generate synthetic queries based on documents provided and implement RAG tests.
An introductory guide to SDG using Ragas: GitHub Repo Link: https://github.com/deeptidabral/AIE5/blob/main/07_Synthetic_Data_Generation_and_LangSmith/Synthetic_Data_Generation_RAGAS_%26_LangSmith_Assignment.ipynb
Basic terminology to understand the meaning of the synthesizer functions:
Query Complexity:
(a) Single-hop: Requires information from one source
(b) Multi-hop: Requires combining information from multiple sources
Reasoning Level:
(a) Specific: Focuses on concrete facts and details
(b) Abstract: Requires synthesis and higher-level reasoning
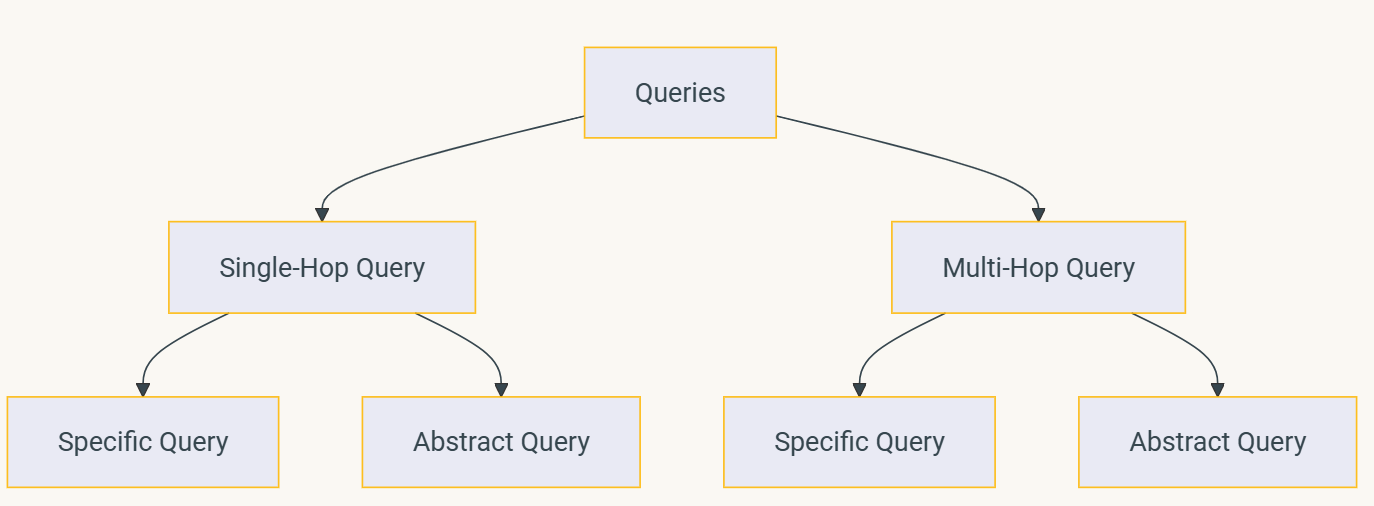 Image Source: https://docs.ragas.io/en/stable/concepts/test_data_generation/rag/
Image Source: https://docs.ragas.io/en/stable/concepts/test_data_generation/rag/
The three query synthesizers of Ragas serve three different purposes when generating synthetic queries.
1. SingleHopSpecificQuerySynthesizer: This generates queries that directly correspond to a single document or passage and works by synthesizing queries that explicitly reference the given information without requiring additional reasoning or combining multiple sources. This is relevant for use cases requiring direct fact extraction tasks. Sample query: “What was Taylor Swift born?”
2. MultiHopAbstractQuerySynthesizer: This creates complex queries that require reasoning / inference / generalization across multiple documents / sources, but in an abstract way. This is most relevant for testing RAGs designed to aggregate multiple pieces of information to answer a query. Sample query: “Create a comparative summary of working in investment banking versus social sector after as a business school graduate.”
3. MultiHopSpecificQuerySynthesizer: This generates complex queries that require retrieving multiple documents and mentioning specific details. It creates queries requiring fact linkage across multiple sources (inputs to RAG systems). Sample query: “What is the annual compensation range of a business school graduate in investment banking versus social sector in NYC?”
By viewing the synthetic data samples generated in app.ragas.io, we can understand questions generated by each type of QuerySynthesizer in an easier way.
Hence, these different synthesizers enable evaluation of RAG systems by generating different types of synthetic queries, from simple fact-based ones to complex multi-hop reasoning queries.
RAGAS library has a wide set of robust evaluators to assess the quality of RAG systems, Agent applications, and other tasks which I will be discussing in another post on evaluating RAG.
APPENDIX
References
- https://arxiv.org/pdf/2403.04190
- https://aws.amazon.com/what-is/synthetic-data/
- https://arxiv.org/pdf/2409.12437
- https://mostly.ai/what-is-synthetic-data
- https://docs.sdv.dev/sdmetrics/metrics/metrics-glossary
- https://arxiv.org/html/2402.07712
- https://arxiv.org/html/2410.10865v1/
- https://docs.ragas.io/en/stable/
- https://www.moveworks.com/us/en/resources/blog/synthetic-data-for-ai-development
- https://docs.ragas.io/en/v0.1.21/concepts/testset_generation.html
- https://docs.ragas.io/en/latest/getstarted/rag_testset_generation/#knowledgegraph-creation