
A comprehensive framework for evaluation of RAG Systems - Part 1
1. Introduction to RAG
An LLM based application can suffer from significant challenges of limited context, hallucinations (generating fake, fabricated information), and lack of ability to update itself. The most popular solution to deal with these issues has turned out to be the Retrieval Augmented Generation (RAG) architecture. In this blog, I have focused on how we can holistically and diligently evaluate these RAG applications. But first, a quick overview of the LLM application workflows with and without RAG to understand the value of RAG. Throughout this blog, I will use the example of a banking chatbot to discuss the core concepts.
1.1 How is the RAG workflow different from a traditional LLM-based workflow?
LLM Chatbot
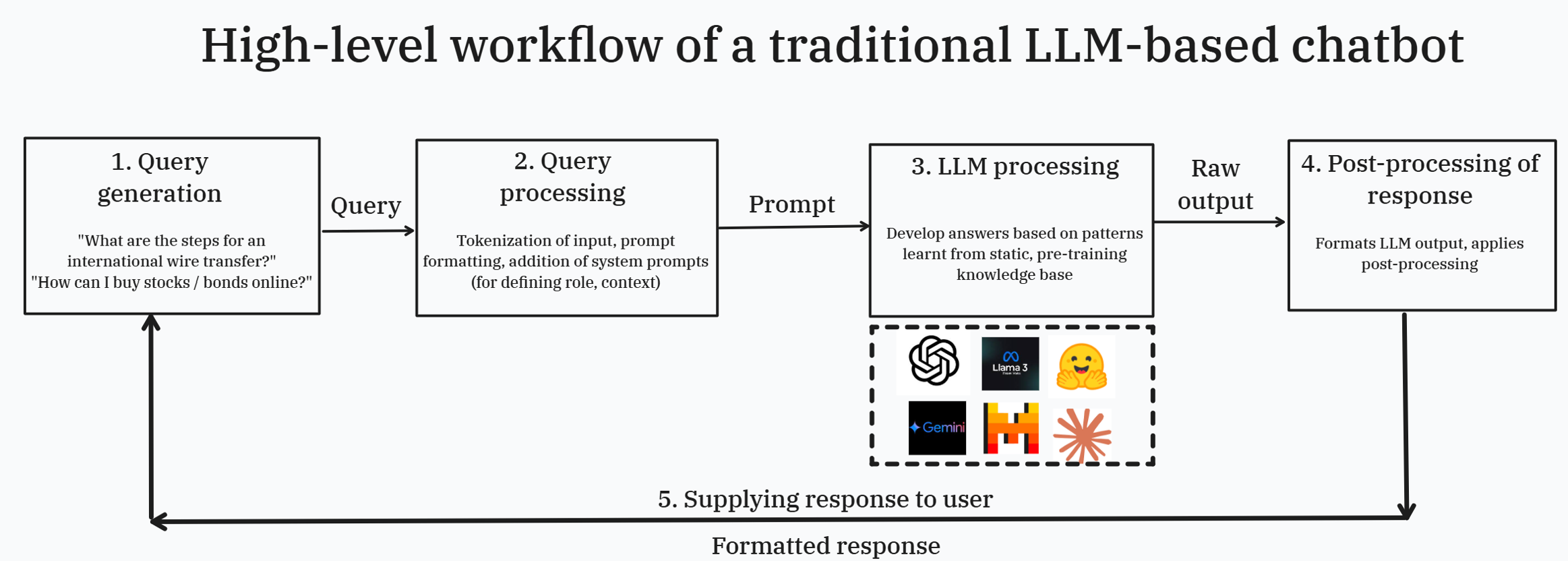
Let’s consider the example of a customer service chatbot of a bank enabled by an LLM. Querying this chatbot invokes the following sequence of steps at a high-level:
- Query generation – A user enters a query (e.g., How can I buy the product XYZ? What are the steps for an international wire transfer?) in the chatbot UI.
- Query processing – Here, the query is tokenized (text decomposed into smaller meaningful units called tokens), applicable constraints (e.g., ensure not to give any investment advice or tax guidance) or information filters (e.g., do not respond if critical input fields are missing) are applied, and overall prompt is formatted via addition of system prompts with context to the prompt template (e.g., specifying the role of the chatbot “a helpful assistant”, key instructions to generate the responses “if you don’t know, then respond with “I don’t know””). This step is crucial to prepare the input for effective processing by the LLM.
- LLM processing – The LLM accesses its internal knowledge representations to generate the query response (through neural pathway activation, weight adjustments across layers, and pattern recognition through the transformer architecture – More on this in another write-up). The LLMs work with their pre-trained knowledge base defined till a particular cut-off date.
- Post-processing of response – The raw output is formatted, cleaned up, standardized and prepared for user consumption.
- Response delivery – The formatted response is delivered to the end user. There are more nuances around error handling, session management, context retention that are not covered in this high-level overview but merit discussion when looking at this in more detail from an implementation perspective. While well-equipped to handle basic queries about the bank’s policies and processes, this workflow risks providing outdated information (since responses are based solely on training date limited to a prior cut-off date).
RAG-powered LLM Chatbot
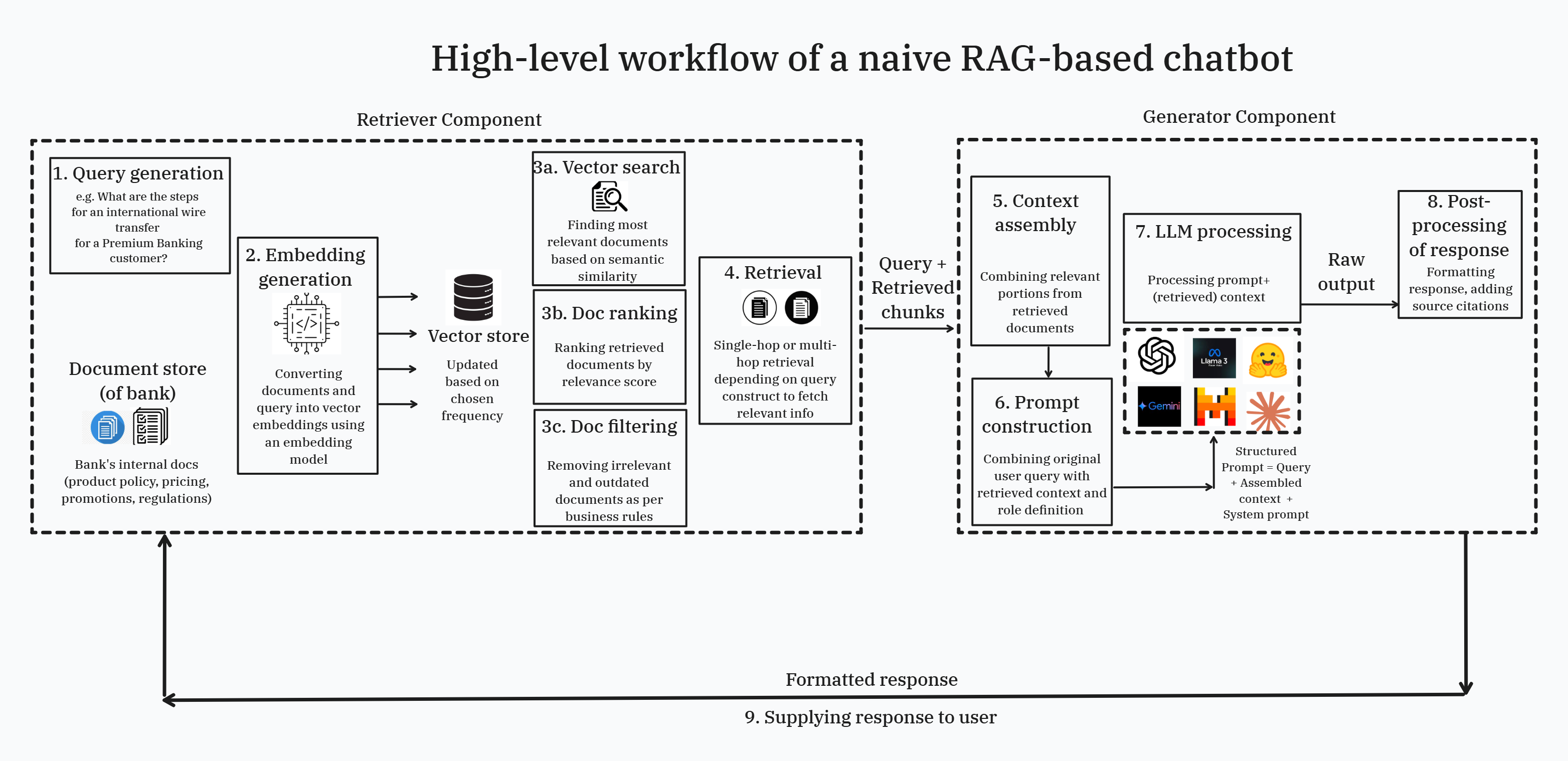
Continuing with the same example of a customer service chatbot of a bank, let’s see how this workflow changes when the chatbot is additionally powered by RAG design.
- Query generation – A user enters a query (e.g., How can I buy the product XYZ? What are the steps for an international wire transfer?) in the chatbot UI.
- Embedding generation – An embedding model is used to convert the user query into a vector representation, the same one used to vectorize the knowledge base (external to the LLM such as bank’s product and policy documents) so that the reference documents are also stored using the same vector representation.
- Vector search, document ranking, and document filtering – Semantic similarity matching is done to find documents most contextually relevant for the user query. This is followed by document ranking based on relevance score (by using re-ranking algorithms such as cross-encoder). Finally, document filtering (e.g., contextual filtering, metadata filtering, content-based) is performed to refine and curate the knowledge base retrieved for LLMs.
- Retrieval (Single-hop or multi-hop) – Based on the query requirements, the retrieval might need only a single extraction of information (single-hop retrieval) to answer a direct, straightforward question or might involve multiple extractions (single-hop retrieval) from multiple sources for reasoning-based questions that need multiple pieces of evidence. This step returns multiple chunks of information based on the retrieval.
- Context assembly – Relevant portions from retrieved documents are combined and put into a coherent context making this information more relevant for the LLM. Poor assembly can dilute the impact of high-quality outputs of effective retrievals.
- Prompt construction – Retrieved context chunks, query, and response format instructions are combined to create the overall prompt crucial for effective processing by the LLM.
- LLM processing – The well-structured prompt (query + top-most relevant documents + response format instructions) is now fed into the LLM that generates a contextually aware response integrating retrieved facts with its pretrained knowledge. Since the LLM is conditioned to generate responses based on this database only, this ensures that all responses are grounded in factual information only.
- Post-processing of response – The raw output is formatted, cleaned up, standardized, source citations are added (to provide grounding evidence), and prepared for user consumption.
- Response delivery – The formatted response is delivered to the end user. This RAG-powered chatbot deals with the above-mentioned challenges of an LLM-only chatbot as follows:
• RAG removes the limitation of limited context by retrieving additional sources of information and enhancing the input prompt for LLMs.
• Via advanced context processing techniques of re-ranking, and filtering), RAG improves factual correctness and accuracy of the chatbot by generating responses grounded in actual evidence preventing hallucinations.
• RAG allows dynamic updates by supporting real-time data retrievals and updates.
While RAG is powerful wrt introducing tangible advantages in LLM applications, as Anthropic suggests sometimes a simple solution such as using a longer prompt which includes the entire knowledge base (~20k tokens from ~500 pages) might work the best for Claude (Anthropic’s LLMs) models.
1.2 What are the challenges in RAG evaluation?
There are several key factors that make RAG evaluation challenging:
- Complex queries requiring advanced information synthesis: User queries requiring inter-linking of sources to develop logical and reasoning-driven answers necessitate multi-hop retrievals. The complexities of synthesizing information from multiple retrieved chunks in RAG make it difficult to ensure synthesis quality while avoiding loss of critical context. E.g., when answering a customer’s query about their eligibility for credit limit increase (CLI) on their credit card, the system must correctly synthesize information from a customer’s credit profile, account history, repayment behaviour, credit bureau reports, and bank’s product-specific regulations around internal risk assessment policies, income thresholds and permissible credit limits.
- Multi-modular architecture: The dual modules of retrieval and generation introduce high potential for error compounding, and propagation across the pipeline. Poor quality retrieval can lead to errors in information synthesis and therefore, generation. This means retrieval quality directly impacts generation quality. E.g., failure of the retrieval module to fetch the latest, most up-to-date risk assessment policies would lead to inaccurate response and thus, invalid communication with the customer.
- Trade-off between context preservation versus relevance: There is a classic trade-off between context window size and relevance of retrieved content while maintaining practical performance. A longer context window implies larger retrieved documents preserving vital context but leads to longer latency and redundancy. A shorter context window reduces redundancy and improves speed / performance but risks loss of critical context. This means there is a need to evaluate multiple chunking strategies to find the most optimal one for a particular use case-domain combination. E.g., when answering a customer’s query about their eligibility for credit limit increase (CLI) on their credit card, a chatbot needs to find the optimal balance between: a. extracting long-term repayment history of 12 months which provides comprehensive creditworthiness assessment but increases latency, versus b. extracting short-term repayment history of 3 months which enables fast response delivery but can potentially miss richer patterns about customer behavior
- Need for dynamic knowledge updates: Due to regular updates of knowledge base, RAG system behavior would also drift / evolve / change, making historical validations / evaluations no longer valid and requiring more frequent validation experiments. This need for temporal consistency underlines the need for regular RAG evaluation. E.g., since product-specific terms and conditions can change over time, the chatbot must be able to leverage this updated information via timely retrievals in its responses.
- Non-determinism of LLM outputs: Since the LLM outputs are non-deterministic (valid but different responses for the same query across different iterations), RAG systems need advanced reference-based metrics for evaluation instead of traditional reference-based metrics. E.g., when explaining terms and conditions of a product, the system can rephrase that explanation in different ways making their comparisons difficult even if all of them are truthful and valid.
- Ground Truth Challenges: While the RAG generated answers explicitly cite sources ensuring grounding, human expert knowledge is still needed for determining correctness of the system. Integrating human expertise is essential but creating these high-quality benchmarks is costly and time-consuming. E.g., responding accurately to customer queries about complex products such as derivatives could require expert inputs and validations from product experts with deep expertise of product features, regulatory landscape, and value proposition for the customer.
- Domain Specificity: For understanding the overall system performance, the requirements for domain-specific accuracy metrics, specialized evaluation criteria. These must be further nuanced or revised with domain expertise of humans. E.g., while informing the customer about the international wire transfer process, the system should check for exact process as well as compliance with regulations related to fund transfers across borders, applicable fee components, and any other disclosure requirements.
- Edge case testing: It might be hard to test the RAG systems for rare, edge cases – scenarios that involve intersecting conditions that make them both rare and complex to handle. There might be limited availability of datasets with these kinds of edge scenarios making reliability testing of the system harder. Careful and calibrated synthetic data generation could help here. E.g., handling queries about releasing the hold / freeze on an account while the bank has flagged fraudulent transactions – less frequent scenarios but critical to handle correctly.
- Evaluation Metric Limitations: Traditional metrics (e.g., BLEU, ROUGE that are too strict focused on exact word matching) don’t capture all quality aspects such as semantic faithfulness necessitating need for an array of complementary metrics around various dimensions of retrieval quality, generation quality, answer accuracy, and consistency. Since several of these metrics need to be balanced against each other, optimizing them as a whole is always effort-intensive and challenging. E.g., Evaluation of responses to user queries about investment products requires looking out for not just accuracy but also regulatory compliance, risk disclosure requirements, and appropriateness of recommendations.
- Cost and Resource Constraints: Continuous and comprehensive RAG evaluation is expensive with regard to time and resources. This means efficient and standardized evaluation methodologies (with critical feedback loops integrating human expertise) are critical to ensure scalable and effective testing achieving depth (detailed quality assessment) and coverage (all dimensions are evaluated). E.g., evaluating a chatbot’s performance across multiple categories of queries (product, risk, advisory, compliance) in face of evolving financial industry landscape requires ongoing and nuanced efforts to understand response quality implying significant investment in infrastructure and testing methodology.
2. Understanding RAG Assessement Framework
2.1 What makes RAG evaluation fundamentally different from traditional LLM evaluation?
Evaluation of traditional LLM systems is focused on quality of generation. However, due to various above-mentioned challenges associated with RAG evaluation, evaluation of RAG systems requires a multi-layered approach to ensure its reliability, trustworthiness, fairness and accuracy. Due to these differences in architecture and knowledge systems of the two options, RAG evaluation is fundamentally different from traditional LLM evaluation in the following ways:
| Source of difference in evaluation | Traditional LLM application | RAG-powered LLM evaluation |
|---|---|---|
| 1. Architecture | Focused on the model’s ability to process and generate text. | Need to evaluate both the retrieval mechanism and the generation component. Retrieval system’s effectiveness (in finding relevant documents) greatly impacts the final output quality, despite LLM performing perfectly. |
| 2. Context-dependence of correctness | Measured against a fixed ground truth or an expected output | Correctness is context-dependent - an answer might be valid as per retrieved documents, but still incorrect if the retrieval is poor and inaccurate. |
| 3. Error attribution and analysis | Simpler | More complex since error could stem from either poor retrieval OR good retrieval but poor ranking and selection OR poor integration, hallucinations |
| 4. Temporal consistency | Works with a fixed knowledge cutoff date | Assess if system is using latest information and maintaining logical consistency across responses about the same topic |
| 5. Multi-hop reasoning complexity | Performed on LLM’s pre-trained knowledge base | Assess the ability to perform multiple retrieval steps requiring the system to be able to decompose questions and synthesize information across multiple sources |
| 6. Source attribution | Evaluated based on output quality | Check if the system can accurately trace back the answers back to specific sources |
| 7. Retrieval efficiency | Not applicable due to absence of retrieval module | Should account for computational and time efficiency of retrieval |
These core differences require developing and leveraging evaluation frameworks and metrics specifically designed for RAG systems.
2.2 What is a holistic RAG evaluation framework? What are the core components that need to be evaluated in a RAG system?
A holistic RAG assessment requires evaluating its core components of retrieval, generation and the overall system with respect to the user experience it delivers. Evaluation of each category requires careful consideration and analysis along with human expert inputs. The evaluation begins with analysing retrieval performance, where context relevance is the primary metric for measuring information retrieval effectiveness. The assessment then requires assessing generation quality composed of answer relevance, faithfulness, correctness, and citation accuracy to determine the accuracy and reliability of the generated responses. Finally, we evaluate the user experience to determine the overall system performance.
(A) Retrieval Evaluation:
- Contextual Relevance: measures how well the system retrieves precisely targeted information that addresses the query, optimizing computational efficiency by minimizing extraneous content.
(B) Generative Evaluation:
- Answer Relevance evaluates whether the generated response directly addresses the query’s requirements, with penalties for incomplete or superfluous content.
- Faithfulness assesses how accurately the generated response reflects the retrieved context, ensuring all statements can be traced back to the source materials and identifying potential hallucinations and validating factual correctness.
- Correctness compares the generated response against human experts / human annotators - validated reference answers (“golden passages”) to validate factual accuracy of the answers.
- Citation Quality evaluates the accuracy and appropriateness of source citations in generated outputs, calculated by averaging citation precision and recall scores across all referenced citations.
(C) User Experience Evaluation: • In addition to the above metrics, RAG systems require additional evaluations such as assessing robustness to noise in documents, latency, and response diversity.
• Metrics related to computational and time efficiency of retrieval aren’t relevant for evaluation of traditional LLM applications because they operate on a fixed knowledge base that’s baked into their model weights during training. Querying a traditional LLM will trigger the simple, straightforward workflow sketched above which includes processing the input prompt, accessing the LLM’s internal knowledge representation through parameter activations, and generating the response. This is relatively uniform in terms of computational requirements.
• In contrast, as seen in the workflows above, RAG systems have additional components of vector database search, document chunking and embedding, similarity computation, and context window management.
• Thus, RAG performance time depends on multiple factors such as size of document collection, # of relevant documents, document length, # of multiple retrievals needed, and vector store performance. This is why RAG evaluation must consider these additional metrics that determine user experience. There are a few options for evaluators to pursue evaluation of each dimension.
(1) Lexical evaluators rely on exact word matching techniques and statistical calculations, employing metrics like keyword frequency and Mean Reciprocal Rank (MRR) to assess how well the document text aligns with queries at a surface level. However, this approach does not considers deeper meaning of the text.
(2) Semantic evaluators are oriented with meaning-based analysis, measuring the conceptual alignment between queries and documents by analysing contextual relationships and thematic connections. This helps capture the query intent and the documents allowing for relevance-based evaluation rather than plain keyword matching.
(3) LLM as a judge evaluators use LLMs to assess content quality by determining coherence, accuracy, and relevance through their broad language understanding capabilities.
But before we deep-dive into these metrics, it is important to understand their fundamental building blocks especially about the confusion matrix for a RAG.
RAG Evaluation Confusion Matrix
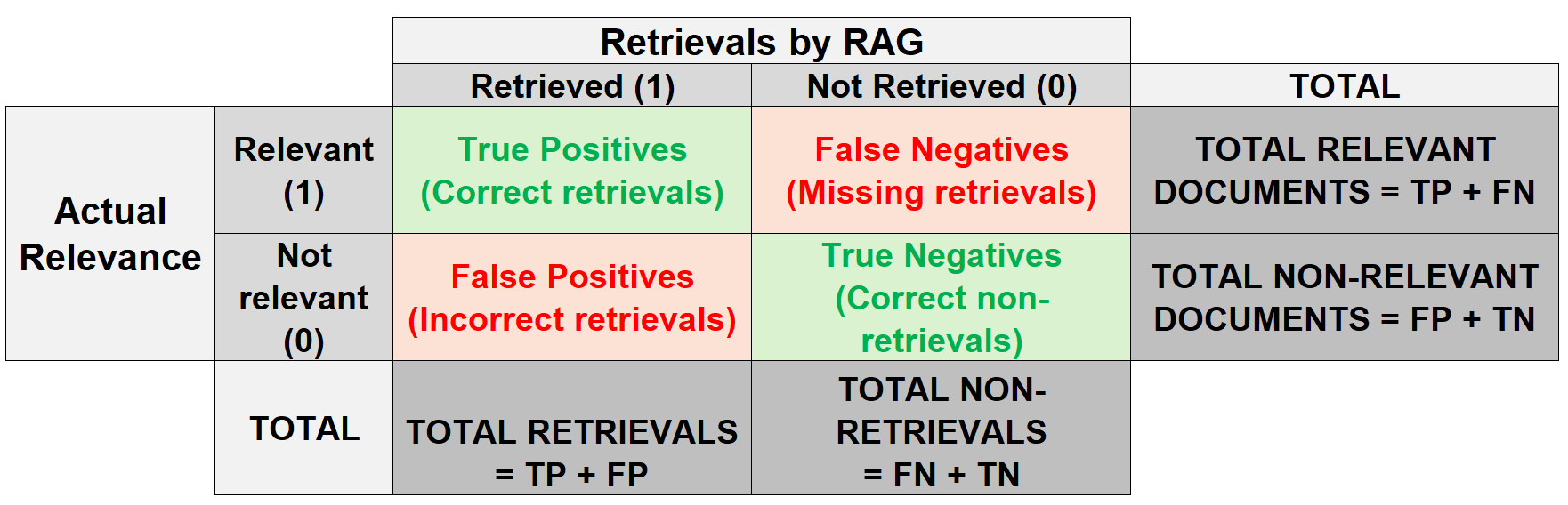
| Metric | Formula | Definition |
|---|---|---|
| Accuracy | (TP+TN)/(TP+FP+TN+FN) | Overall correct retrieval rate including both relevant and irrelevant documents |
| Precision | TP / (TP+FP) | Measures how many retrieved documents were relevant |
| Recall / True Positive Rate (TPR) / Sensitivity | TP / (TP+FN) | Measures how many relevant documents were successfully retrieved |
| F1 score | 2 PR /(P+R); harmonic mean of Precision and Recall | Balanced measure between Precision and Recall |
Examples of each category of the RAG Evaluation Confusion Matrix:
| Category of confusion matrix | Explanation | User Query | Retrieval / non-retrieval | Outcome |
|---|---|---|---|---|
| True positives | Retrievals that are relevant | What’s the minimum balance for avoiding fees on a checking account? | Document about checking account minimum balance requirements | Correct and relevant information retrieved |
| True negatives | Non-retrievals that are not relevant | What’s the current mortgage rate? | Documents about both mortgage rates AND auto loan rates | Auto loan information is irrelevant and shouldn’t have been retrieved |
| False positives | Retrievals that are not relevant | How do I dispute a fraudulent transaction? | General fraud prevention guidelines | Missed retrieving the specific document about transaction dispute procedures |
| False negatives | Non-retrievals that are relevant | How do I set up direct deposit? | NR: Documents about loan applications or investment products | Correctly excluded unrelated banking documents |
Image Source: Benchmarking of Retrieval Augmented Generation: A Comprehensive Systematic Literature Review on Evaluation Dimensions, Evaluation Metrics and Datasets
A comprehensive RAG evaluation framework to be sufficient needs automated metrics for basic quality checks, expert review for critical cases and enough samples, continuous monitoring in production, and regular updates to evaluation criteria as the domain and landscape of the use case evolves.
| Performance evaluation | Evaluation Dimensions | Evaluator | Metric | Definition | Formula | Interpretation |
|---|---|---|---|---|---|---|
| 1: Retrieval evaluation | Context Relevance | Lexical matching | 1a: Context Precision / Precision@k | Measures relevancy of retrieved context to prompt, conveying the quality of retrieval pipeline | (# of relevant retrieved passages) / (# of total retrieved passages) | b/w 0 and 1; higher the better |
| Lexical matching | 1b: Context Recall / Recall @k | Measures recall of the retrieved context (measures how many relevant passages are captured within the top k retrieved chunks) and thus, the ability to retrieve all necessary information | (# of relevant retrieved passages) / (# of total relevant passages) | b/w 0 and 1; higher the better | ||
| Lexical matching | 1c: Mean Reciprocal Rank / MRR@k | Calculates context relevance by emphasizing the rank of the first relevant passage across multiple queries | Average of the reciprocal ranks of the first relevant passage across a set of queries | A higher MRR indicates that RAG is consistently ranking relevant passages higher in the retrieval results, crucial for providing accurate responses. | ||
| LLM as a judge | 1d: Context Relevance Score (CRS) | Indicates the proportion of the context that is relevant | (# of relevant sentences extracted from the context) / (# of total sentences in the context) | A higher score indicates that a greater proportion of the retrieved context is focused and relevant for answering the query, while a lower score indicates that much of the retrieved context contains irrelevant information. | ||
| 2: Generation evaluation | Answer Relevance | LLM as a judge | 2a: Answer Relevance Score (ARS) | Measures how well the generated answer matches the intent and content of the original question; An answer is deemed relevant when it directly and appropriately addresses the original question; Mean cosine similarity between the embeddings of the generated questions and the original query q | Obtained by averaging the similarity between the generated questions and the original query; where sim (qi, q) represents the cosine similarity between the embeddings of the generated questionsand the original query q | b/w 0 and 1; higher the better |
| Faithfulness | Lexical matching | 2b: K-Precision | Evaluates the degree of faithfulness since it has the highest agreement with human judgements; proportion of tokens in the LLMs response that are present in the retrieved context, i.e., it is the overlap of matching tokens with the retrieved context divided by the total number of tokens in the response | (# matched tokens) / (# response tokens) | Higher the value, better the RAG system | |
| LLM as a judge | 2c: Faithfulness coefficient (FC) | Evaluates whether the responses are supported, contradicted or not supported by the retrieved context. | Faithfulness Score / # of responses | 1 for “full” match b/w response and retrieved context, 0.5 for “partial” match, and 0 for “no match at all” | ||
| LLM as a judge | 2d: Faithfulness score (FS) | The answer a(q) is considered faithful to the context c(q) if the statements in the LLM response can be directly inferred from the retrieved context. | # of supported statements / # total number of statements; where a supported statement is one that is supported by the information in the retrieved context | Higher the value, better the RAG system | ||
| Correctness | Lexical matching | 2e: Recall | Measures how much of the reference answer’s essential content is captured in the model’s response without penalizing additional information | (Relevant tokens in passage) / (Total relevant tokens in Golden-passage) where “golden passage” is provided by human annotators | % of all relevant information was actually retrieved; Low recall suggests the retriever might be missing important information | |
| LLM as a judge | 2f: Correctness coefficient (CC) | Evaluates whether the model response is correct, partially correct, or incorrect where correctness of responses is determined by prompting the LLMs with the question, the reference answer, and the LLM’s response | average of all response scores = sum of all correct responses / # total responses | 1 for “fully correct”, 0.5 for “partially”, and 0 for “incorrect” | ||
| Citation Quality | LLM as a judge | 2g: Citation recall | Assesses whether all generated statements are substantiated by the citations | (# claims with citations) / (# claims requiring citations) | Higher is better (1.0 is perfect). It measures completeness of citations, shows if system is citing all necessary claims and is important for transparency and verifiability. | |
| LLM as a judge | 2h: Citation precision | Checks whether all cited passages are relevant and necessary for the statements made and identifies any “irrelevant” citations, i.e., those that do not independently support a statement or are not necessary when other citations already provide full support | (# correct citations) / (# total citations) | Higher is better (1.0 is perfect). It measures accuracy of citations, indicates system’s ability to link claims to correct sources, and is critical for accountability and fact-checking. | ||
| 3:User Experience Metrics | Latency | NA since this is a computational metric | 3a: Single query latency | Mean time is taken to process a single query, including both retrieval and generating phases | Total time taken to complete steps 1 to 9 in the workflow schematic above | Lower is better. It helps identify bottlenecks in RAG pipeline and indicates system scalability and efficiency. |
| Diversity in generation | Lexical and semantic evaluator | 3b: Cosine similarity / cosine distance | Calculates embeddings of retrieved documents or generated responses | Standard formula of cosine similarity | Lower scores indicate higher diversity, suggesting that the system can retrieve or generate a broader spectrum of information. | |
| Noise robustness | LLM as a judge | 3c: Misleading rate (M-Rate) | Where a response is considered “misleading” if it: (a) Contains factually incorrect information derived from noisy data, (b) Presents information that contradicts the ground truth, (c) Combines information incorrectly due to noisy retrievals | (# of misleading responses) / (# total responses) | Lower M-Rate is better and indicative of how often the system provides incorrect information due to noise. Assesses the system’s resilience to noisy data. | |
| Semantic evaluator | 3d: Mistake reappearance rate | Where a “repeated mistake” is: (a) A previously identified error that occurs again in subsequent responses, (b) The same type of factual error appearing across different queries, (c) Consistent misinterpretation of noisy data points | (# of repeated mistakes) / (# total identified mistakes) | Lower rate is better and measures the system’s ability to learn from and avoid repeating mistakes. High rate suggests systematic issues in handling noisy data. Helps identify persistent noise-related problems in the knowledge base. | ||
| Negative rejection | Lexical matching | 3e: Rejection rate | The rate at which the system refrains from generating a response; used to measure negative rejection; When only noisy documents are provided, LLMs should output the specific content – “I cannot answer the question because of the insufficient information in documents.” If the model generates this content, it indicates a successful rejection. | (# of correctly rejected queries) / (# total out-of-scope queries) Where: -“Out-of-scope queries” are questions the system should not attempt to answer -“Correctly rejected” means system recognized its inability to provide accurate information | Higher rate is better. It measures system’s ability to recognize its limitations and indicates responsible handling of out-of-scope queries. This is critical for maintaining trust and accuracy. | |
| Counterfactual robustness | Lexical matching | 3f: Error detection rate | Measures whether the model can detect the factual errors in the documents for counterfactual robustness. When the provided documents contain factual errors, the model should output the specific content – “There are factual errors in the provided documents.” If the model generates this content, it indicates that the model has detected erroneous information in the document. | (# of correctly identified errors) / (# total number of errors) Where: -“Errors” are factual inconsistencies or counterfactual statements -“Correctly identified” means system recognized and flagged the error | Higher rate is better and demonstrates the system’s ability to identify problematic information and thus, helps prevent error propagation. | |
| Lexical matching | 3g: Error correction rate | Measures whether the model can provide the correct answer after identifying errors for counterfactual robustness. The model is asked to generate the correct answer after identifying the factual errors. If the model generates the correct answer, it indicates that the model is capable of correcting errors in the document. | (# of successfully corrected errors)/(# of detected errors) Where: -“Successfully corrected” means system provided accurate information instead of erroneous content -Includes both automatic corrections and flagged items requiring human review | Higher rate is better and it measures system’s ability to recover from identified errors indicating robustness of correction mechanisms. |
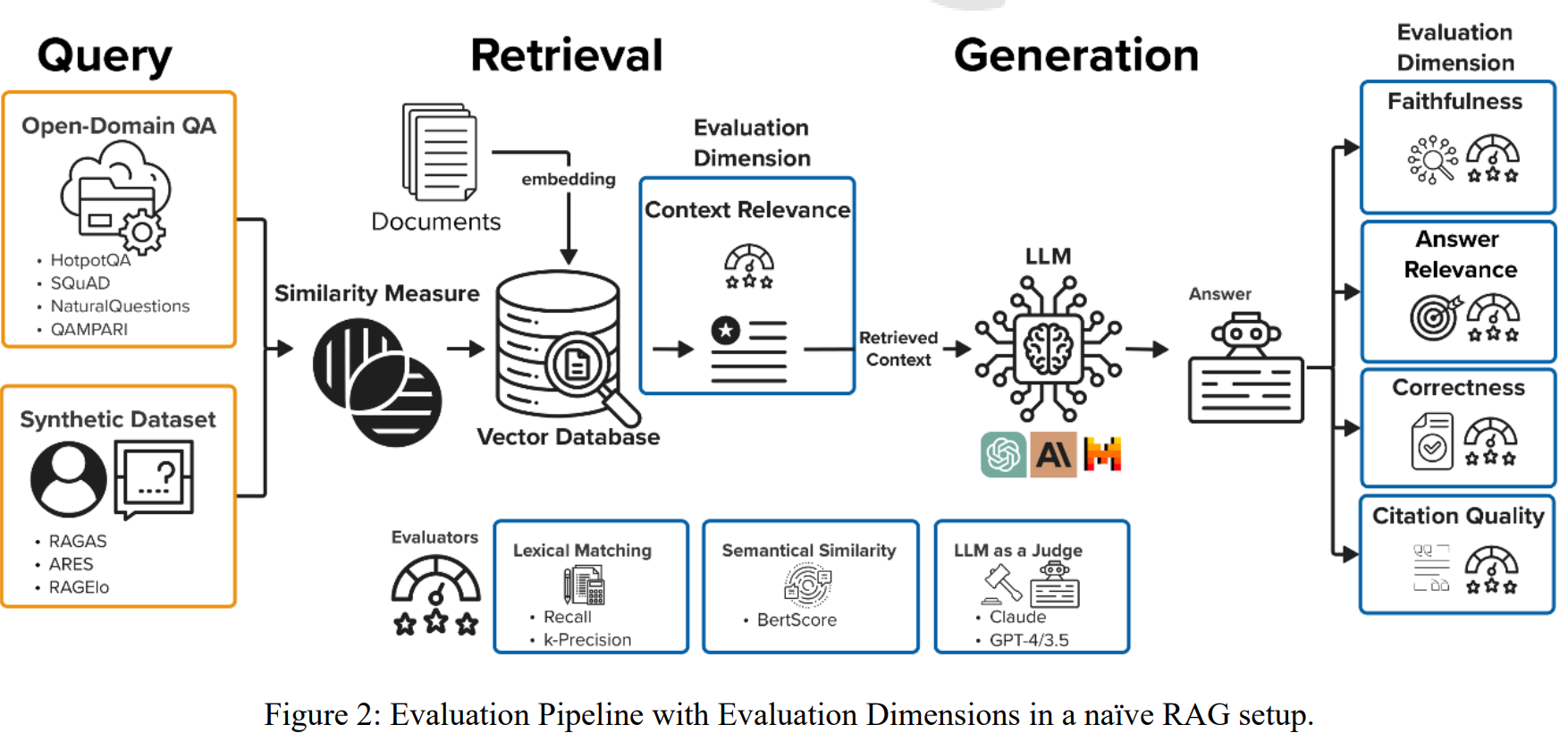 Image Source:
Image Source: 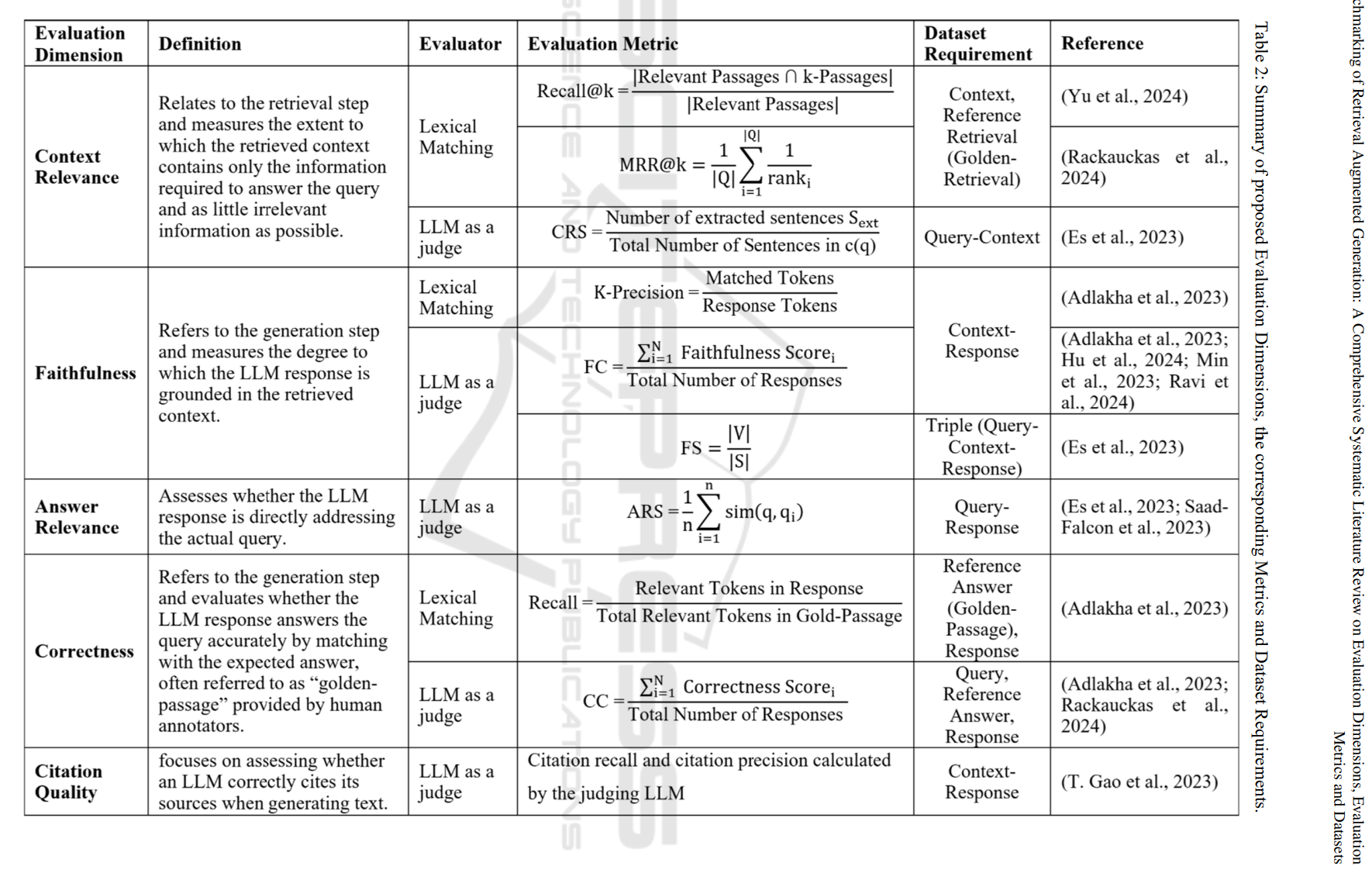 Image Source:
Image Source: